Você sabia que o CEP brasileiro não é apenas um código para entregas? Ele carrega informações geográficas hierárquicas que podem ser usadas para inferir características socioeconômicas dos seus leads — mesmo quando você não tem dados diretos sobre eles.
Neste post, vou mostrar como construí um modelo simples de lead scoring usando apenas o CEP como feature, aplicando estimativas bayesianas para priorizar leads com maior probabilidade de conversão.
Mas, Janderson, o que é um lead e porque ele precisa de um score?
Bom, lead geralmente é entendimento como um cliente potencial que deixou uma forma de você se comunicar com ele, podendo ser um e-mail, telefone, rede social, endereço, etc. Em uma área de vendas, saber pra quem vender é uma das chaves do sucesso, então rankear os melhores possíveis clientes faz parte da inteligência do negócio.
A estrutura do CEP brasileiro
O Código de Endereçamento Postal (CEP) foi criado pelos Correios em 1972 e possui uma estrutura hierárquica de 8 dígitos que vai do geral ao específico:
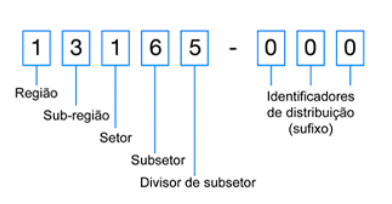
Os primeiros dígitos contam uma história
O primeiro dígito divide o Brasil em grandes zonas:
| Dígito | Região |
|---|---|
| 0 | Grande São Paulo |
| 1 | Interior de São Paulo |
| 2 | Rio de Janeiro e Espírito Santo |
| 3 | Minas Gerais |
| 4 | Bahia e Sergipe |
| 5 | Pernambuco, Alagoas, Paraíba e Rio Grande do Norte |
| 6 | Ceará, Piauí, Maranhão, Pará, Amazonas, Acre, Amapá e Roraima |
| 7 | Distrito Federal, Goiás, Tocantins, Mato Grosso, Mato Grosso do Sul e Rondônia |
| 8 | Paraná e Santa Catarina |
| 9 | Rio Grande do Sul |
Os dois primeiros dígitos refinam ainda mais a localização. Por exemplo, dentro de São Paulo capital:
- 01: Centro, Consolação, Bela Vista, Jardins
- 04: Moema, Itaim Bibi, Vila Olímpia
- 05: Pinheiros, Perdizes, Lapa
Essa granularidade é exatamente o que precisei para análises. Bairros com CEPs iniciando em “01” ou “04” em São Paulo tendem a ter perfil socioeconômico muito diferente de bairros com CEPs iniciando em “08” (zona leste).
O problema: priorizar leads sem dados
Imagine o cenário: você tem uma base de 120 mil leads que demonstraram interesse em fazer intercâmbio. Desses, apenas 25% responderam um formulário de contato/qualificação com informações como faixa de renda. Os outros 75% são uma incógnita. Como priorizar o contato da equipe de vendas?
Uma das soluções é usar o CEP como proxy para renda. A lógica é simples:
- Leads que responderam o formulário nos dão a relação CEP → Renda
- Apliquei essa relação nos leads que não responderam
- Priorizei leads de regiões com maior renda estimada
PS: Esse tipo de abordagem só faz sentido no Brasil devido a nossa desigualdade social. Tendemos sempre a ter bairros reconhecidamente de ‘rico’ e bairros de ‘pobre’.
O modelo: Estimativa Bayesiana por CEP
Por que Bayesiano?
Um problema comum ao agrupar por CEP é a esparsidade de dados. Você pode ter milhares de observações para CEP “01” (centro de SP), mas apenas 3 para CEP “69” (interior do Amazonas).
Calcular a média diretamente geraria estimativas muito instáveis para regiões com poucos dados. A solução é usar shrinkage bayesiano, que consiste em “puxar” estimativas extremas em direção à média quando temos poucos dados.
média_bayesiana = (n × média_local + k × média_global) / (n + k)
Onde:
n= número de observações na regiãok= peso do prior (quanto menor n, maior k)- Regiões com poucos dados são “puxadas” para a média global
Mas, Janderson, por que “bayesiano”? Porque usa um conhecimento prévio (a média global) para ajustar a estimativa quando a evidência local é fraca. É o princípio de Bayes: combinar prior (o que já sabemos) com dados novos.
Fallback hierárquico
Nem todo CEP terá dados de treino. Usei a hierarquia do CEP para fallback/plano de ação:
CEP-5 (01310) → CEP-3 (013) → CEP-2 (01) → Média Global
Se não tenho dados para o CEP específico “01310”, uso a média do CEP “013”. Se ainda não tiver, uso “01”, e assim por diante.
Implementação em Python
Estrutura dos dados
Trabalhei com três bases sintéticas:
# interesse.csv: todos os leads
# Colunas: data_interesse, cpf, email, cep
# formulario.csv: leads que responderam qualificação
# Colunas: data_resposta, cpf, intervalo_renda
# intervalo_renda:
# 1: "-R$2.000",
# 2: "R$2.000–4.000",
# 3: "R$4.000–8.000",
# 4: "R$8.000–12.000",
# 5: "+R$12.000"
# compras.csv: leads que converteram
# Colunas: data_compra, cpf, destino, cep
O modelo
class ModeloRendaCEP:
"""Modelo bayesiano hierárquico de renda por CEP."""
def __init__(self):
self.media_global = None
self.stats_cep5 = None
self.stats_cep3 = None
self.stats_cep2 = None
def fit(self, df, col_renda="intervalo_renda_num"):
"""
Treina o modelo usando dados de formulário.
IMPORTANTE: usar todos os respondentes do formulário,
não apenas compradores (evita selection bias).
"""
self.media_global = df[col_renda].mean()
# Calcular estatísticas bayesianas para cada nível
self.stats_cep5 = calcular_stats_bayesianas(df, "cep5", col_renda, self.media_global)
self.stats_cep3 = calcular_stats_bayesianas(df, "cep3", col_renda, self.media_global)
self.stats_cep2 = calcular_stats_bayesianas(df, "cep2", col_renda, self.media_global)
return self
def predict(self, df):
"""
Aplica o modelo com fallback hierárquico:
CEP-5 → CEP-3 → CEP-2 → média global
"""
# ... joins e fallback ...
# Score final: 90% renda + 10% confiança
df["score_final"] = ((df["renda_estimada"] - 1) / 4) * 90 + df["confianca"] * 10
return df
Cálculo das estatísticas bayesianas
def calcular_stats_bayesianas(df, col_cep, col_renda, media_global):
stats = df.groupby(col_cep)[col_renda].agg(["count", "mean"]).reset_index()
stats.columns = ["chave_cep", "n_obs", "media_local"]
# k = peso do prior (menos dados → mais shrinkage)
def calcular_k(n):
if n >= 50: return 1
elif n >= 10: return 3
else: return 5
stats["k"] = stats["n_obs"].apply(calcular_k)
# Média bayesiana
stats["media_bayes"] = (
(stats["n_obs"] * stats["media_local"] + stats["k"] * media_global)
/ (stats["n_obs"] + stats["k"])
)
# Confiança: proporção do dado local na estimativa
stats["confianca"] = stats["n_obs"] / (stats["n_obs"] + stats["k"])
return stats
Resultados
Resumindo:
flowchart TD
%% ======= ESTILOS =======
classDef db fill:#e1f5fe,stroke:#01579b,stroke-width:2px;
classDef process fill:#f3e5f5,stroke:#4a148c,stroke-width:2px,stroke-dasharray: 5 5;
classDef final fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px;
classDef model fill:#fff3e0,stroke:#e65100,stroke-width:2px;
classDef eval fill:#fce4ec,stroke:#880e4f,stroke-width:2px;
%% ======= GRUPO 1: DADOS ORIGINAIS =======
subgraph Raw_Data [Bases Brutas]
direction TB
INTERESSE[("interesse.csv<br/>120.000 leads<br/>(Data, CPF, Email, CEP)")]:::db
FORMULARIO[("formulario.csv<br/>30.000 respostas<br/>(Data, CPF, Renda)")]:::db
COMPRAS[("compras.csv<br/>7.962 conversões<br/>(Data, CPF, Destino, CEP)")]:::db
end
%% ======= GRUPO 2: PREPARAÇÃO =======
subgraph Preparation [Preparação dos Dados]
direction TB
BASE_TREINO["Base de Treino<br/>Formulário + CEP do Interesse<br/>(30.000 leads com renda conhecida)"]
SPLIT["Split 80/20"]
TREINO["Treino<br/>24.000 leads"]:::final
VALIDACAO["Validação<br/>6.000 leads"]:::process
BASE_SCORING["Base de Scoring<br/>Interesse completo<br/>(120.000 leads)"]
end
%% ======= GRUPO 3: MODELAGEM =======
subgraph Modeling [Modelo Bayesiano]
direction TB
STATS_CEP{{"Estatísticas por CEP<br/>────────────────<br/>CEP-5: 9.625 únicos<br/>CEP-3: 120 únicos<br/>CEP-2: 12 únicos"}}:::model
MODELO{{"Modelo de Renda<br/>────────────────<br/>Média Bayesiana com Shrinkage<br/>Fallback: CEP5→CEP3→CEP2→Global"}}:::model
SCORE{{"Score Final<br/>────────────────<br/>90% Renda Estimada<br/>10% Confiança"}}:::model
end
%% ======= GRUPO 4: AVALIAÇÃO =======
subgraph Evaluation [Avaliação do Modelo]
direction TB
EVAL_RENDA(("Validação de Renda<br/>────────────────<br/>Correlação: 0.633<br/>Precision@100: 100%<br/>Lift: 1.46x")):::eval
EVAL_CONV(("Backtest de Conversão<br/>────────────────<br/>Top decil: 8.44%<br/>Baseline: 6.64%<br/>Lift: 1.27x")):::eval
end
%% ======= GRUPO 5: OUTPUT =======
subgraph Output [Resultado Final]
LEADS_SCOREADOS[("leads_scoreados.csv<br/>120.000 leads<br/>(CPF, CEP, Score, Renda Est.)")]:::final
end
%% ======= CONEXÕES =======
%% Preparação da base de treino
INTERESSE --> BASE_TREINO
FORMULARIO --> BASE_TREINO
%% Split treino/validação
BASE_TREINO --> SPLIT
SPLIT --> TREINO
SPLIT --> VALIDACAO
%% Preparação da base de scoring
INTERESSE --> BASE_SCORING
COMPRAS -. "Flag: comprou" .-> BASE_SCORING
%% Treinamento do modelo
TREINO ==> STATS_CEP
STATS_CEP ==> MODELO
MODELO ==> SCORE
%% Aplicação e avaliação
SCORE --> VALIDACAO
VALIDACAO --> EVAL_RENDA
SCORE --> BASE_SCORING
BASE_SCORING --> EVAL_CONV
%% Output final
BASE_SCORING --> LEADS_SCOREADOS
Validação da predição de renda
Testei o modelo em 6.000 leads que responderam o formulário (mas não foram usados no treino):
| Métrica | Valor |
|---|---|
| Correlação real × estimada | 0.633 |
| Precision@100 (alta renda) | 100% |
| Lift vs baseline | 1.46× |
O modelo consegue identificar leads de alta renda com precisão quase perfeita nos top 100. O Lift é quantas vezes melhor o modelo é comparado ao acaso (baseline). O Precision@100 trouxe pra mim dos 100 leads com maior score, quantos são realmente de alta renda.
Backtest de conversão
O Backtest é uma forma de testar um modelo em dados históricos para ver se ele teria funcionado no passado. Sendo assim, aplicando o modelo em 120 mil leads e comparando com quem realmente converteu:
| Decil | Taxa de Conversão | vs Baseline |
|---|---|---|
| 9 (top) | 8.44% | +27% |
| 8 | 7.29% | +10% |
| … | … | … |
| 1 | 5.76% | -13% |
| 0 (bottom) | 3.94% | -41% |
O top decil converte 2.14× mais que o bottom decil.
Curva de ganho
A curva de ganho mostra quanto você “ganha” ao usar o modelo para priorizar, comparado com escolher aleatoriamente. No meu caso, tenho as seguintes informações quando priorizo leads pelo score:
- Top 10% da base captura 12.6% das conversões (lift 1.26×)
- Top 20% captura 23.6% das conversões
- Top 50% captura 57% das conversões
Na prática, isso significa que a equipe de vendas pode focar em metade da base e ainda capturar mais da metade das vendas potenciais.
Visualizações
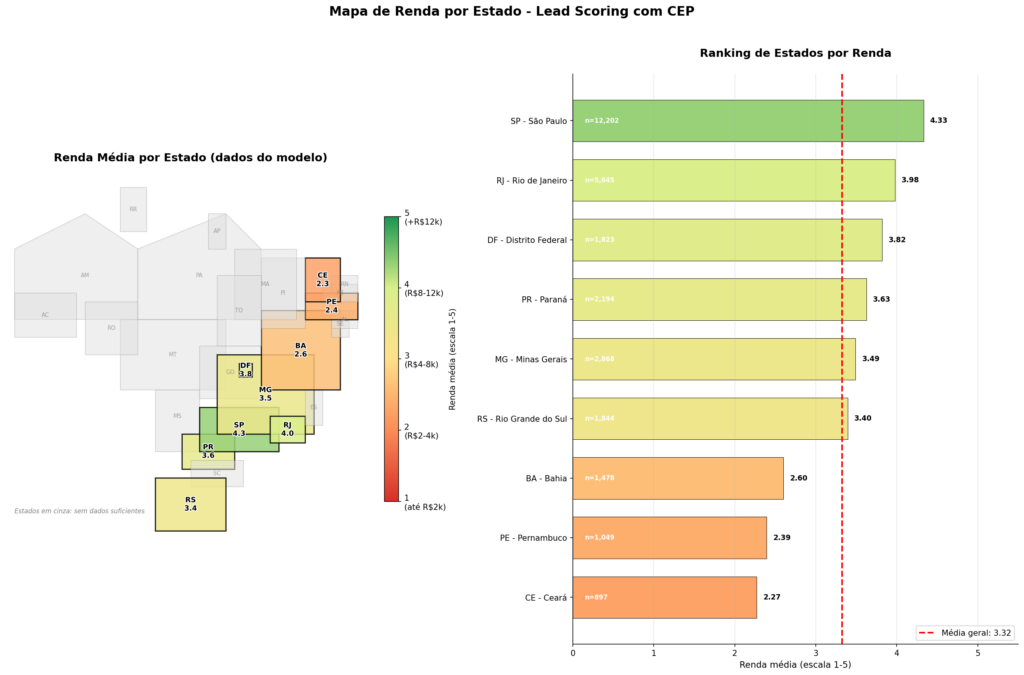
Renda média por região
O gráfico acima mostra a renda média (escala 1-5) por CEP-2. Note a clara diferença entre regiões:
- CEPs 01, 04, 22: Renda média acima de 4 (Jardins/SP, Zona Sul/RJ)
- CEPs 40, 50, 60: Renda média abaixo de 3 (Nordeste)
Distribuição de scores
A distribuição de scores (primeiro gráfico) entre conversores (verde) e não-conversores (cinza) mostra uma clara separação — conversores tendem a ter scores mais altos.
Curva de lift
O modelo mantém lift acima de 1 (linha vermelha) para aproximadamente os primeiros 70% da base ordenada por score.
Cuidados importantes
1. Selection bias na base de treino
O erro mais comum é treinar o modelo apenas com dados de quem comprou. Isso cria um viés: você aprende a renda média dos compradores por região, não da população geral.
Errado:
base_treino = compras.merge(formulario, on="cpf") # Só compradores!
Correto:
base_treino = formulario # Todos que responderam
2. CEP como string
CEPs que começam com zero (como “01310100” de São Paulo) perdem o zero quando lidos como número. Sempre force a leitura como string:
df = pd.read_csv("dados.csv", dtype={"cep": str, "cpf": str})
3. Limitações do modelo
O CEP é um proxy imperfeito para renda. Existem pessoas de alta renda em bairros populares e vice-versa. O modelo funciona bem em agregado, mas não deve ser usado para decisões individuais de crédito ou discriminação.
Conclusão
A estrutura hierárquica do CEP brasileiro é uma ferramenta poderosa para análises geográficas. Combinada com técnicas bayesianas para lidar com dados esparsos, permite construir modelos de scoring eficazes mesmo com informações limitadas.
O código completo está disponível no repositório do projeto. Os dados usados são sintéticos, mas a metodologia é aplicável a casos reais.
Principais aprendizados:
- O CEP tem estrutura hierárquica que pode ser explorada (CEP-2, CEP-3, CEP-5)
- Shrinkage bayesiano resolve o problema de regiões com poucos dados
- A base de treino deve incluir todos os respondentes, não só conversores
- Sempre trate CEP e CPF como strings para preservar zeros à esquerda
Alternativas
Caso você queira obter dados de uma rua usando o CEP, o ViaCEP é uma ótima opção. Basta você usar https://viacep.com.br/ws/29210040/json/, substituindo o CEP. A aplicação retorna um json com os dados, incluindo outros dados como SIAFI e código do IBGE.
O Correio não possui uma API para CEP, mas disponibiliza para venda o Diretório Nacional de Endereços (DNE), que é um banco de dados com arquivos nos formatos MS-Access (.mdb) e texto (.txt) que contém mais de 900 mil CEPs de todo o Brasil. Esse produto é vendido na loja do Correios (mas estava fora do ar quando escrevi esse post!)
Gostou do conteúdo? Compartilhe com alguém que trabalha com dados de marketing! 😀
Deixe um comentário