
TF-IDF (Term Frequency-Inverse Document Frequency) é uma técnica fundamental em processamento de linguagem natural que nos permite quantificar a importância de palavras em documentos. Imagine que você tem uma coleção de textos e quer identificar quais palavras são mais características ou distintivas de cada documento – é exatamente isso que o TF-IDF faz.
A métrica combina dois conceitos:
- TF (Term Frequency): Quão frequentemente uma palavra aparece em um documento específico (ou seja, uma contagem, algo que todo mundo está acostumado)
- IDF (Inverse Document Frequency): Quão rara ou comum essa palavra é em toda a coleção de documentos (esse é o pulo do gato).
A Matemática por Trás do TF-IDF
Term Frequency (TF)
A frequência do termo pode ser calculada de diferentes formas. A mais simples é:
 = {n(t,d)} / {N_d}")
Onde, no numerador, temos ‘Número de vezes que t aparece em d’ e no denominador temos ‘Total de termos em d’
Inverse Document Frequency (IDF)
O IDF penaliza termos que aparecem em muitos documentos:
 = log{ {N} / {|{d in D : t in d}|} }")
Onde:
- N = número total de documentos
- |{d ∈ D : t ∈ d}| = número de documentos onde o termo t aparece
TF-IDF Final
TF-IDF(t,d,D) = TF(t,d) × IDF(t,D)
Implementação Prática em Python
Primeiro, vamos importar as bibliotecas necessárias. O scikit-learn já possui uma implementação otimizada do TF-IDF que utilizaremos:
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import seaborn as sns2. Criando um Dataset de Exemplo
Vamos criar um conjunto de documentos para demonstrar o funcionamento do TF-IDF:
# Criando documentos de exemplo sobre diferentes tópicos
documentos = [
"Python é uma linguagem de programação poderosa e versátil",
"Machine learning utiliza algoritmos para aprender padrões nos dados",
"Análise de dados com Python é muito eficiente e popular",
"Deep learning é uma subcategoria do machine learning",
"Visualização de dados ajuda na interpretação de resultados",
"Pandas é uma biblioteca Python essencial para análise de dados"
]
# Criando labels para identificar os documentos
labels = ['Python', 'ML', 'Análise', 'Deep Learning', 'Visualização', 'Pandas']3. Implementando TF-IDF com Scikit-Learn
Agora vamos aplicar o TF-IDF aos nossos documentos. O TfidfVectorizer do scikit-learn faz todo o trabalho pesado para nós:
# Criando o vetorizador TF-IDF
vectorizer = TfidfVectorizer(
max_features=100, # Máximo de features/palavras
stop_words=None, # Não removemos stop words neste exemplo
ngram_range=(1, 1), # Apenas unigramas
lowercase=True, # Converter para minúsculas
token_pattern=r'\b[a-zA-ZÀ-ÿ]+\b' # Pattern para tokens em português
)
# Aplicando TF-IDF aos documentos
tfidf_matrix = vectorizer.fit_transform(documentos)
# Obtendo os nomes das features (palavras)
feature_names = vectorizer.get_feature_names_out()4. Analisando os Resultados
Vamos criar um DataFrame para visualizar melhor os resultados:
# Convertendo a matriz esparsa para array denso
tfidf_dense = tfidf_matrix.toarray()
# Criando DataFrame para análise
df_tfidf = pd.DataFrame(
tfidf_dense,
columns=feature_names,
index=labels
)
# Exibindo as palavras mais importantes para cada documento
print("Top 5 palavras mais importantes por documento:")
for i, doc_label in enumerate(labels):
# Obtendo os top 5 scores para este documento
top_scores = df_tfidf.iloc[i].nlargest(5)
print(f"\n{doc_label}:")
for palavra, score in top_scores.items():
print(f" {palavra}: {score:.4f}")Top 5 palavras mais importantes por documento:
Python:
linguagem: 0.3973
poderosa: 0.3973
programação: 0.3973
versátil: 0.3973
e: 0.3258
ML:
algoritmos: 0.3684
aprender: 0.3684
nos: 0.3684
padrões: 0.3684
utiliza: 0.3684
Análise:
com: 0.3812
eficiente: 0.3812
muito: 0.3812
popular: 0.3812
análise: 0.3126
Deep Learning:
learning: 0.6115
...
essencial: 0.3965
pandas: 0.3965
análise: 0.3252
para: 0.3252Code language: CSS (css)5. Visualizando os Resultados
Criar um heatmap nos ajuda a visualizar a importância das palavras across documentos:
# Selecionando apenas as palavras mais importantes para visualização
top_words = df_tfidf.max().nlargest(15).index
df_viz = df_tfidf[top_words]
# Criando o heatmap
plt.figure(figsize=(12, 8))
sns.heatmap(
df_viz.T, # Transposta para palavras no eixo Y
annot=True,
fmt='.3f',
cmap='YlOrRd',
cbar_kws={'label': 'TF-IDF Score'}
)
plt.title('TF-IDF Scores - Top 15 Palavras por Documento')
plt.xlabel('Documentos')
plt.ylabel('Palavras')
plt.tight_layout()
plt.show()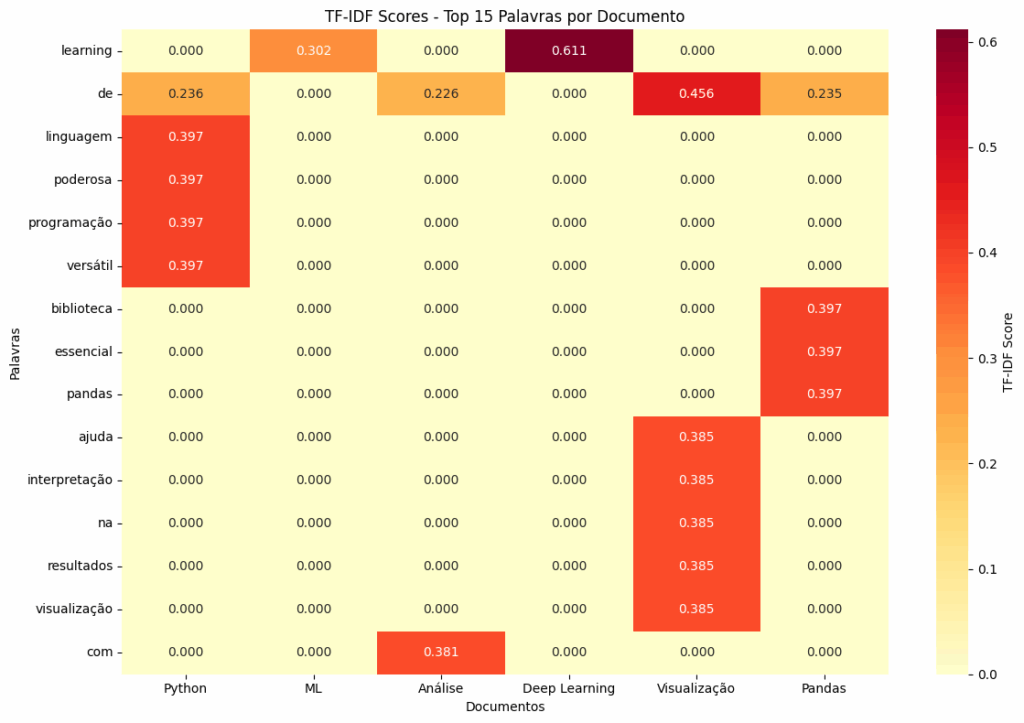
6. Implementação Manual do TF-IDF
Para fins educacionais, vamos implementar o TF-IDF do zero para entender melhor o algoritmo:
import math
from collections import Counter
def calcular_tf(documento):
"""Calcula a Term Frequency para um documento"""
palavras = documento.lower().split()
total_palavras = len(palavras)
contador = Counter(palavras)
tf = {}
for palavra, freq in contador.items():
tf[palavra] = freq / total_palavras
return tf
def calcular_idf(documentos):
"""Calcula o Inverse Document Frequency para toda a coleção"""
N = len(documentos)
todas_palavras = set()
# Coletando todas as palavras únicas
for doc in documentos:
palavras = set(doc.lower().split())
todas_palavras.update(palavras)
idf = {}
for palavra in todas_palavras:
docs_com_palavra = sum(1 for doc in documentos if palavra in doc.lower().split())
idf[palavra] = math.log(N / docs_com_palavra)
return idf
def calcular_tfidf_manual(documentos):
"""Calcula TF-IDF manualmente para todos os documentos"""
# Calculando IDF para toda a coleção
idf_scores = calcular_idf(documentos)
# Calculando TF-IDF para cada documento
tfidf_docs = []
for doc in documentos:
tf_scores = calcular_tf(doc)
tfidf_doc = {}
for palavra, tf in tf_scores.items():
tfidf_doc[palavra] = tf * idf_scores[palavra]
tfidf_docs.append(tfidf_doc)
return tfidf_docs
# Aplicando nossa implementação manual
tfidf_manual = calcular_tfidf_manual(documentos)
# Exibindo resultados da implementação manual
print("Implementação Manual - Top 3 palavras por documento:")
for i, (tfidf_doc, label) in enumerate(zip(tfidf_manual, labels)):
top_3 = sorted(tfidf_doc.items(), key=lambda x: x[1], reverse=True)[:3]
print(f"\n{label}:")
for palavra, score in top_3:
print(f" {palavra}: {score:.4f}")7. Aplicação Prática: Similaridade entre Documentos
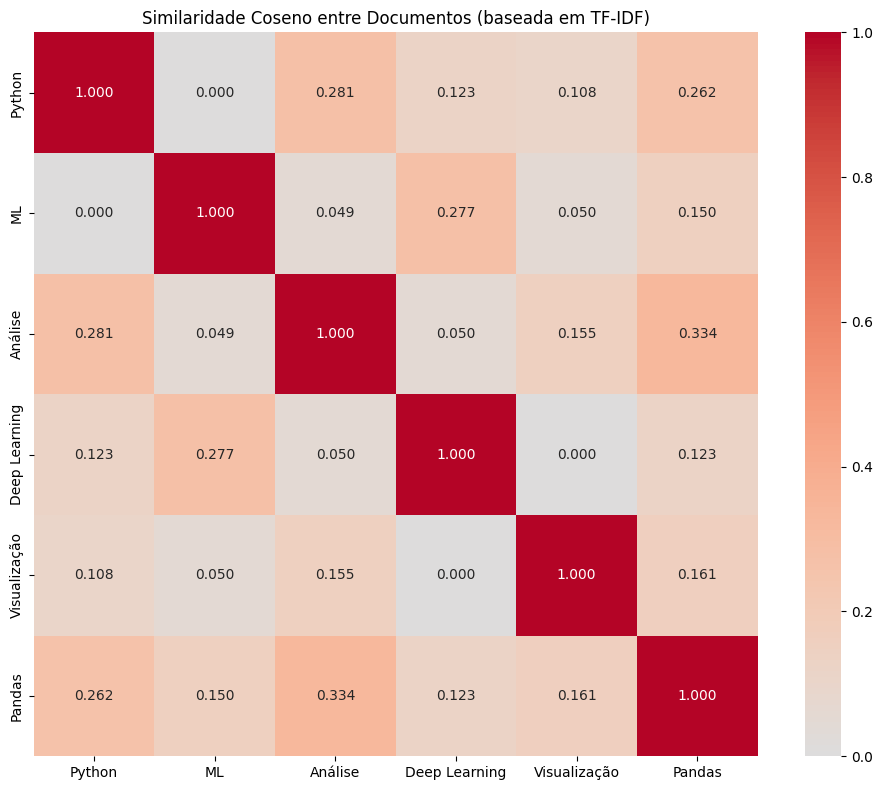
Uma aplicação comum do TF-IDF é calcular a similaridade entre documentos:
# Calculando similaridade coseno entre documentos
similarity_matrix = cosine_similarity(tfidf_matrix)
# Criando DataFrame para visualizar similaridades
df_similarity = pd.DataFrame(
similarity_matrix,
index=labels,
columns=labels
)
# Visualizando a matriz de similaridade
plt.figure(figsize=(10, 8))
sns.heatmap(
df_similarity,
annot=True,
fmt='.3f',
cmap='coolwarm',
center=0,
square=True
)
plt.title('Similaridade Coseno entre Documentos (baseada em TF-IDF)')
plt.tight_layout()
plt.show()
# Encontrando os documentos mais similares
def encontrar_similares(doc_index, top_n=2):
"""Encontra os documentos mais similares a um dado documento"""
similarities = df_similarity.iloc[doc_index].sort_values(ascending=False)
# Excluindo o próprio documento (similaridade = 1)
similares = similarities[1:top_n+1]
print(f"Documentos mais similares a '{labels[doc_index]}':")
for doc, score in similares.items():
print(f" {doc}: {score:.4f}")
# Exemplo: encontrando documentos similares ao primeiro
encontrar_similares(0)Documentos mais similares a 'Python':
Análise: 0.2811
Pandas: 0.2619Code language: JavaScript (javascript)Vantagens e Limitações do TF-IDF
Vantagens:
- Simplicidade: Fácil de entender e implementar
- Eficiência: Computacionalmente eficiente
- Interpretabilidade: Resultados são facilmente interpretáveis
- Redução de dimensionalidade: Naturalmente filtra palavras menos importantes
Limitações:
- Semântica: Não captura relações semânticas entre palavras
- Contexto: Não considera a ordem das palavras
- Sinônimos: Palavras com mesmo significado são tratadas como diferentes
- Esparsidade: Resulta em matrizes muito esparsas para grandes vocabulários
Dicas Avançadas para Melhorar os Resultados
1. Pré-processamento de Texto
import string
import unicodedata
def preprocessar_texto(texto):
"""Pré-processa texto para melhorar resultados do TF-IDF"""
# Converter para minúsculas
texto = texto.lower()
# Remover acentos
texto = unicodedata.normalize('NFD', texto)
texto = ''.join(char for char in texto if unicodedata.category(char) != 'Mn')
# Remover pontuação
texto = texto.translate(str.maketrans('', '', string.punctuation))
# Remover números
texto = ''.join(char for char in texto if not char.isdigit())
return texto
# Aplicando pré-processamento
documentos_processados = [preprocessar_texto(doc) for doc in documentos]2. Configurações Avançadas do TfidfVectorizer
# Vetorizador com configurações otimizadas
vectorizer_avancado = TfidfVectorizer(
max_features=1000, # Máximo de features
min_df=2, # Palavra deve aparecer em pelo menos 2 documentos
max_df=0.8, # Palavra não pode aparecer em mais de 80% dos documentos
ngram_range=(1, 2), # Unigramas e bigramas
sublinear_tf=True, # Usar escala logarítmica para TF
use_idf=True, # Usar IDF
smooth_idf=True, # Suavizar IDF
norm='l2' # Normalização L2
)Conclusão
O TF-IDF é uma ferramenta fundamental em processamento de linguagem natural que nos permite transformar texto em representações numéricas significativas. Embora seja uma técnica relativamente simples, ela continua sendo amplamente utilizada devido à sua eficiência e interpretabilidade.
Com a implementação em Python mostrada neste post, você pode aplicar TF-IDF em seus próprios projetos de análise de texto, desde análise de sentimentos até sistemas de recomendação baseados em conteúdo.
Lembre-se de que o pré-processamento adequado do texto e a escolha correta dos parâmetros do vetorizador são cruciais para obter bons resultados!
Deixe um comentário