Imagine que um cliente viu um anúncio no Meta Ads, depois pesquisou a marca no Google Search, clicou em um anúncio do Google Ads, recebeu um email promocional, viu um vídeo no YouTube Ads e finalmente comprou através de um link de afiliado. Caminho gigante neh? Mas fica a pergunta:
Qual canal merece o crédito pela conversão?
É aqui que entram os modelos de atribuição – metodologias, amplamente conhecida e muitas vezes ignorada, que determinam como distribuir o crédito de uma conversão entre os diferentes pontos de contato (touchpoints) na jornada do cliente.
Por que os Modelos de Atribuição são importantes?
- Otimização de Budget: Saber quais canais realmente convertem ajuda a alocar melhor o investimento;
- Compreensão da Jornada: Entender como os clientes interagem com sua marca;
- ROI Real: Medir o verdadeiro retorno de cada canal de marketing;
- Tomada de Decisão: Basear estratégias em dados, não em suposições.
Neste post aqui no blog vou trazer alguns pontos bem interessantes sobre a aplicação e a utilização desse modelo.
Principais Modelos de Atribuição
1. First Touch (Primeira Interação)
- Como funciona: Todo o crédito vai para o primeiro canal que o cliente teve contato.
- Quando usar: Para entender awareness e descoberta de marca.
- Limitação: Ignora completamente os canais que nutrem e convertem (aqueles que ficam no meio e no final da jornada).
2. Last Touch (Última Interação)
- Como funciona: Todo o crédito vai para o último canal antes da conversão.
- Quando usar: Para otimizar canais de conversão direta.
- Limitação: Ignora todo o trabalho de construção de consideração (aqueles canais que chamam e nutrem o lead)
3. Linear
- Como funciona: Crédito distribuído igualmente entre todos os touchpoints
- Quando usar: Quando todos os canais são igualmente importantes
- Limitação: Pode supervalorizar touchpoints irrelevantes (e desvalorizar canais relevantes)
4. Time Decay
- Como funciona: Maior peso para interações mais próximas da conversão
- Quando usar: Para campanhas com ciclo de compra curto
- Limitação: Pode subestimar canais de awareness (ou seja, não dá a devida importância para os canais que chamam para a jornada)
5. Position-Based (Full Path) – o que vamos aprofundar nesse post!
O Position-Based é o modelo mais equilibrado e estratégico para a maioria dos negócios. Ele funciona da seguinte forma:
flowchart LR
Start[Início da Jornada] --> A["🧭 Descoberta<br/>(1º Touchpoint)"]
A --> B["🧩 Touchpoints Intermediários<br/>(Nurturing)"]
B --> C["🏁 Conversão<br/>(Último Touchpoint)"]
A --> Acredit["🎯 Crédito: 40%"]
B --> Bcredit["🎯 Crédito: 20%"]
C --> Ccredit["🎯 Crédito: 40%"]
classDef credito fill:#fff3e0,stroke:#f57c00,stroke-width:2px;
class Acredit,Bcredit,Ccredit credito;- 40% do crédito para o primeiro touchpoint (descoberta/awareness)
- 40% do crédito para o último touchpoint (conversão)
- 20% restante dividido igualmente entre os touchpoints intermediários (nurturing)
Por que da escolha pelo Position-Based?
- Equilibra awareness e conversão: Reconhece tanto a importância da descoberta quanto do fechamento;
- Reflete a realidade do marketing: Sabemos que tanto “chamar atenção” quanto “fechar vendas” são cruciais;
- Flexível e customizável: Permite ajustar pesos conforme estratégia do negócio;
- Fácil de explicar: Stakeholders entendem intuitivamente a lógica;
- Dados mais acionáveis: Fornece insights claros para otimização de budget;
A teoria é funciona e é bem estabelcida, mas vamos fazer um exercício e implementar um dos modelos de atribuição, nesse caso o position-based, com dados artificiais de uma jornada de marketing.
Preparação dos Dados
O código abaixo cria um dataset simulado com características do marketing digital, considerando investimento por canal, padrões temporais e distribuições de valores de conversão mais próximas da realidade. Ele é genérico, sendo necessário projetar um dataset específico para cada negócio para análise. :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# Configuração para gráficos mais bonitos
plt.style.use('seaborn-v0_8-whitegrid')
sns.set_palette("husl")
# Criando dados simulados de jornadas de clientes
np.random.seed(42)
# Lista de canais com características de investimento
channels_info = {
'Meta Ads': {'investment_level': 'high', 'avg_ticket': 180, 'peak_hours': [19, 20, 21, 22]},
'Google Ads': {'investment_level': 'high', 'avg_ticket': 220, 'peak_hours': [9, 10, 11, 14, 15, 16]},
'Google Search': {'investment_level': 'medium', 'avg_ticket': 200, 'peak_hours': [9, 10, 11, 14, 15, 16, 20, 21]},
'YouTube Ads': {'investment_level': 'medium', 'avg_ticket': 160, 'peak_hours': [19, 20, 21, 22]},
'TikTok Ads': {'investment_level': 'medium', 'avg_ticket': 140, 'peak_hours': [19, 20, 21, 22, 23]},
'Email': {'investment_level': 'low', 'avg_ticket': 190, 'peak_hours': [8, 9, 10, 19, 20]},
'Afiliados': {'investment_level': 'medium', 'avg_ticket': 170, 'peak_hours': [10, 11, 14, 15, 16, 20, 21]},
'Direct': {'investment_level': 'organic', 'avg_ticket': 210, 'peak_hours': [9, 10, 11, 14, 15, 16, 20, 21]}
}
channels = list(channels_info.keys())
# Definindo probabilidades baseadas no investimento
investment_weights = {
'Meta Ads': 0.22, # Alto investimento
'Google Ads': 0.20, # Alto investimento
'Google Search': 0.15, # Médio (orgânico + pago)
'YouTube Ads': 0.12, # Médio investimento
'TikTok Ads': 0.10, # Médio investimento
'Email': 0.08, # Baixo investimento
'Afiliados': 0.08, # Médio investimento
'Direct': 0.05 # Orgânico
}
def generate_realistic_timestamp(base_date, touchpoint_order, channel):
"""
Gera timestamps considerando:
- Horários comerciais e início da noite
- Variação por dias da semana
- Padrões específicos por canal
"""
# Espaçamento entre touchpoints (1-7 dias)
days_offset = np.random.choice([0, 1, 2, 3, 4, 5, 6, 7],
p=[0.3, 0.25, 0.15, 0.1, 0.08, 0.07, 0.03, 0.02])
# Data base do touchpoint - convertendo para int padrão do Python
touch_date = base_date + timedelta(days=int(touchpoint_order * days_offset))
# Ajuste para dias da semana (segunda a domingo = 0 a 6)
weekday = touch_date.weekday()
# Horários pico do canal
peak_hours = channels_info[channel]['peak_hours']
# Probabilidade de estar em horário pico vs outros horários
if weekday < 5: # Segunda a sexta
if np.random.random() < 0.7: # 70% chance de horário pico
hour = np.random.choice(peak_hours)
else: # Outros horários comerciais
business_hours = [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]
hour = np.random.choice(business_hours)
else: # Final de semana
if np.random.random() < 0.6: # 60% chance de horário pico
hour = np.random.choice(peak_hours)
else: # Horários mais dispersos no weekend
weekend_hours = [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
hour = np.random.choice(weekend_hours)
# Minutos aleatórios
minute = np.random.randint(0, 60)
return touch_date.replace(hour=hour, minute=minute, second=0, microsecond=0)
def generate_realistic_conversion_value(channel):
"""
Gera valores de conversão usando distribuição log-normal
com tickets médios diferentes por canal
"""
avg_ticket = channels_info[channel]['avg_ticket']
# Usando distribuição log-normal (mais realista para valores monetários)
# Parâmetros ajustados para ter média próxima ao ticket médio do canal
mu = np.log(avg_ticket * 0.8) # Ajuste para média desejada
sigma = 0.6 # Variabilidade
value = np.random.lognormal(mu, sigma)
# Garantindo valores mínimos e máximos realistas
value = max(50, min(value, 2000)) # Entre R$ 50 e R$ 2.000
return round(value, 2)
def generate_realistic_customer_journey():
"""
Gera uma jornada de cliente mais realista considerando:
- Probabilidades baseadas em investimento
- Padrões temporais
- Valores de conversão por distribuição log-normal
"""
# Número de touchpoints com distribuição
num_touchpoints = np.random.choice([1, 2, 3, 4, 5, 6],
p=[0.25, 0.30, 0.25, 0.12, 0.06, 0.02])
# Data base da jornada (últimos 60 dias)
base_date = datetime.now() - timedelta(days=int(np.random.randint(1, 61)))
journey = []
used_channels = set()
for i in range(num_touchpoints):
# Probabilidades ajustadas por posição na jornada
if i == 0: # Primeiro touchpoint - awareness (com peso por investimento)
# Canais pagos de awareness têm maior probabilidade
channel_probs = {
'Meta Ads': 0.28, 'TikTok Ads': 0.18, 'YouTube Ads': 0.15,
'Google Ads': 0.15, 'Google Search': 0.10, 'Direct': 0.08,
'Email': 0.04, 'Afiliados': 0.02
}
elif i == num_touchpoints - 1: # Último touchpoint - conversão
# Canais de bottom-funnel têm maior probabilidade
channel_probs = {
'Google Search': 0.25, 'Google Ads': 0.25, 'Direct': 0.15,
'Email': 0.12, 'Afiliados': 0.10, 'Meta Ads': 0.08,
'YouTube Ads': 0.03, 'TikTok Ads': 0.02
}
else: # Touchpoints intermediários - nurturing
channel_probs = investment_weights.copy()
# Evita repetir o mesmo canal consecutivamente (mais realista)
available_channels = [ch for ch in channels if ch not in used_channels or len(used_channels) >= 6]
if not available_channels:
available_channels = channels
available_probs = [channel_probs[ch] for ch in available_channels]
# Normaliza probabilidades
total_prob = sum(available_probs)
available_probs = [p/total_prob for p in available_probs]
channel = np.random.choice(available_channels, p=available_probs)
used_channels.add(channel)
# Gera timestamp
timestamp = generate_realistic_timestamp(base_date, i, channel)
# Valor de conversão (mesmo para toda a jornada, mas baseado no canal final)
if i == 0: # Define no primeiro touchpoint
final_channel = channel if num_touchpoints == 1 else np.random.choice(
['Google Search', 'Google Ads', 'Direct', 'Email', 'Afiliados'],
p=[0.3, 0.25, 0.2, 0.15, 0.1]
)
conversion_value = generate_realistic_conversion_value(final_channel)
journey.append({
'customer_id': None, # Será preenchido depois
'touchpoint_order': i + 1,
'channel': channel,
'timestamp': timestamp,
'conversion_value': conversion_value,
'weekday': timestamp.strftime('%A'),
'hour': timestamp.hour
})
return journey
# Gerando 1500 jornadas de clientes (mais dados para análise robusta)
print("Gerando dataset realista de jornadas de marketing...")
all_journeys = []
for customer_id in range(1, 1501):
if customer_id % 300 == 0:
print(f" Processando cliente {customer_id}/1500...")
journey = generate_realistic_customer_journey()
for touchpoint in journey:
touchpoint['customer_id'] = customer_id
all_journeys.extend(journey)
# Criando DataFrame
df = pd.DataFrame(all_journeys)
# Garantindo que valor de conversão é o mesmo para toda a jornada do cliente
df['conversion_value'] = df.groupby('customer_id')['conversion_value'].transform('first')
# Adicionando informações úteis para análise
df['is_weekend'] = df['timestamp'].dt.weekday >= 5
df['period'] = df['hour'].apply(lambda x:
'Manhã' if 6 <= x < 12 else
'Tarde' if 12 <= x < 18 else
'Noite' if 18 <= x < 24 else
'Madrugada'
)
print("Dataset criado com sucesso!")
print(f"Estatísticas do Dataset:")
print(f" • Total de touchpoints: {len(df):,}")
print(f" • Total de clientes: {df['customer_id'].nunique():,}")
print(f" • Valor total de conversões: R$ {df.groupby('customer_id')['conversion_value'].first().sum():,.2f}")
print(f" • Ticket médio: R$ {df.groupby('customer_id')['conversion_value'].first().mean():.2f}")
print(f" • Mediana de touchpoints por jornada: {df.groupby('customer_id').size().median():.0f}")
# Análise rápida da distribuição por canal
print(f"\n Distribuição de Touchpoints por Canal:")
channel_distribution = df['channel'].value_counts()
for channel, count in channel_distribution.items():
percentage = (count / len(df)) * 100
print(f" • {channel}: {count:,} touchpoints ({percentage:.1f}%)")
# Análise temporal
print(f"\n Análise Temporal:")
print(f" • Touchpoints em dias úteis: {(~df['is_weekend']).sum():,} ({(~df['is_weekend']).mean()*100:.1f}%)")
print(f" • Touchpoints no fim de semana: {df['is_weekend'].sum():,} ({df['is_weekend'].mean()*100:.1f}%)")
period_dist = df['period'].value_counts()
for period, count in period_dist.items():
percentage = (count / len(df)) * 100
print(f" • {period}: {count:,} touchpoints ({percentage:.1f}%)")
# Visualizações para validar a aproximação com a realidade
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle('Validação do Realismo dos Dados', fontsize=16, fontweight='bold')
# 1. Distribuição de touchpoints por canal
channel_counts = df['channel'].value_counts()
bars1 = ax1.bar(range(len(channel_counts)), channel_counts.values, color='skyblue', alpha=0.8)
ax1.set_title('Distribuição de Touchpoints por Canal', fontweight='bold')
ax1.set_xlabel('Canais')
ax1.set_ylabel('Número de Touchpoints')
ax1.set_xticks(range(len(channel_counts)))
ax1.set_xticklabels(channel_counts.index, rotation=45, ha='right')
# Adicionando valores nas barras
for i, bar in enumerate(bars1):
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2, height + height*0.01,
f'{height:,}', ha='center', va='bottom', fontsize=9)
# 2. Distribuição de valores de conversão (log-normal)
conversion_values = df.groupby('customer_id')['conversion_value'].first()
ax2.hist(conversion_values, bins=50, color='lightcoral', alpha=0.7, edgecolor='black')
ax2.set_title('Distribuição dos Valores de Conversão', fontweight='bold')
ax2.set_xlabel('Valor de Conversão (R$)')
ax2.set_ylabel('Frequência')
ax2.axvline(conversion_values.mean(), color='red', linestyle='--',
label=f'Média: R$ {conversion_values.mean():.2f}')
ax2.axvline(conversion_values.median(), color='orange', linestyle='--',
label=f'Mediana: R$ {conversion_values.median():.2f}')
ax2.legend()
# 3. Padrão temporal por hora do dia
hourly_pattern = df.groupby('hour').size()
ax3.plot(hourly_pattern.index, hourly_pattern.values, marker='o', color='green', linewidth=2)
ax3.set_title('Padrão de Touchpoints por Hora do Dia', fontweight='bold')
ax3.set_xlabel('Hora do Dia')
ax3.set_ylabel('Número de Touchpoints')
ax3.set_xticks(range(0, 24, 2))
ax3.grid(True, alpha=0.3)
# Destacando horários comerciais e noturno
ax3.axvspan(9, 18, alpha=0.2, color='blue', label='Horário Comercial')
ax3.axvspan(19, 22, alpha=0.2, color='orange', label='Início da Noite')
ax3.legend()
# 4. Distribuição por dia da semana
weekday_pattern = df.groupby('weekday').size()
weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_pattern = weekday_pattern.reindex(weekday_order)
bars4 = ax4.bar(range(len(weekday_pattern)), weekday_pattern.values,
color=['lightblue']*5 + ['lightcoral']*2, alpha=0.8)
ax4.set_title('Distribuição por Dia da Semana', fontweight='bold')
ax4.set_xlabel('Dia da Semana')
ax4.set_ylabel('Número de Touchpoints')
ax4.set_xticks(range(len(weekday_pattern)))
ax4.set_xticklabels(['Seg', 'Ter', 'Qua', 'Qui', 'Sex', 'Sáb', 'Dom'])
# Adicionando valores nas barras
for i, bar in enumerate(bars4):
height = bar.get_height()
ax4.text(bar.get_x() + bar.get_width()/2, height + height*0.01,
f'{height:,}', ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.show()
# Análise adicional: Ticket médio por canal
print(f"\n Ticket Médio por Canal:")
ticket_by_channel = df.groupby('customer_id').agg({
'conversion_value': 'first',
'channel': lambda x: x.iloc[-1] # Canal do último touchpoint
}).groupby('channel')['conversion_value'].mean().sort_values(ascending=False)
for channel, avg_ticket in ticket_by_channel.items():
print(f" • {channel}: R$ {avg_ticket:.2f}")Gerando dataset realista de jornadas de marketing...
Processando cliente 300/1500...
Processando cliente 600/1500...
Processando cliente 900/1500...
Processando cliente 1200/1500...
Processando cliente 1500/1500...
Dataset criado com sucesso!
Estatísticas do Dataset:
• Total de touchpoints: 3,759
• Total de clientes: 1,500
• Valor total de conversões: R$ 282,546.47
• Ticket médio: R$ 188.36
• Mediana de touchpoints por jornada: 2
Distribuição de Touchpoints por Canal:
• Google Ads: 681 touchpoints (18.1%)
• Meta Ads: 661 touchpoints (17.6%)
• Google Search: 592 touchpoints (15.7%)
• YouTube Ads: 411 touchpoints (10.9%)
• TikTok Ads: 400 touchpoints (10.6%)
• Direct: 395 touchpoints (10.5%)
• Email: 341 touchpoints (9.1%)
• Afiliados: 278 touchpoints (7.4%)
Análise Temporal:
• Touchpoints em dias úteis: 2,686 (71.5%)
• Touchpoints no fim de semana: 1,073 (28.5%)
• Noite: 1,752 touchpoints (46.6%)
• Tarde: 1,090 touchpoints (29.0%)
• Manhã: 917 touchpoints (24.4%)Code language: HTTP (http)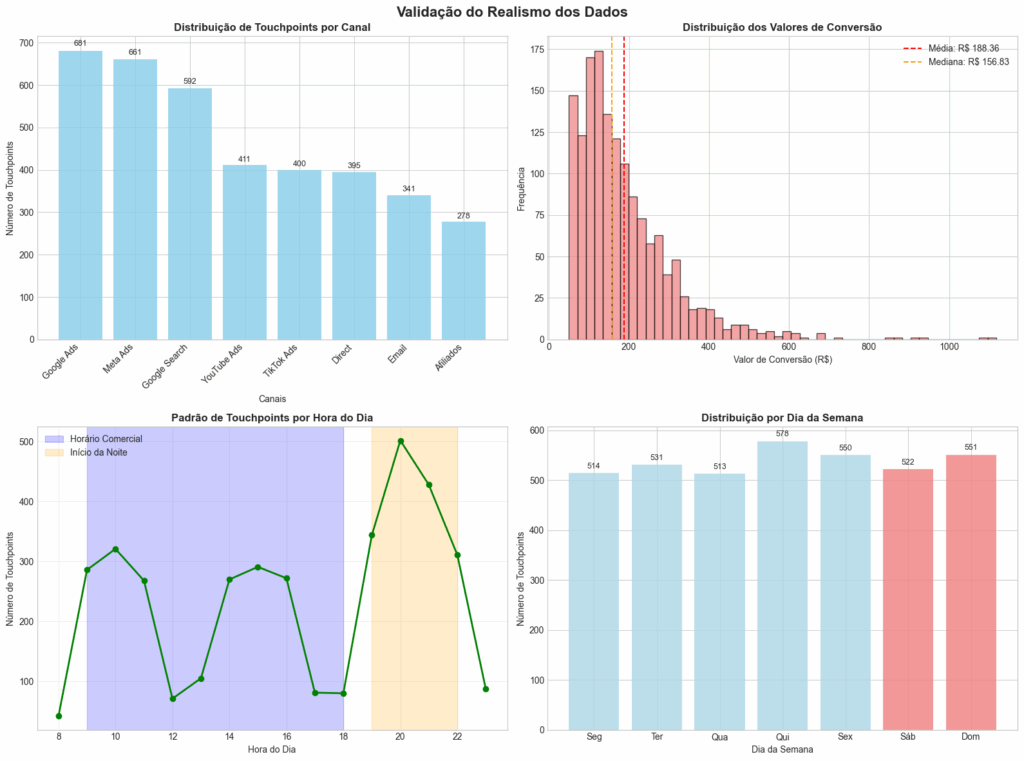
Ticket Médio por Canal:
• Afiliados: R$ 200.57
• Google Ads: R$ 199.37
• Google Search: R$ 195.58
• Direct: R$ 191.99
• Meta Ads: R$ 182.47
• Email: R$ 178.79
• YouTube Ads: R$ 170.55
• TikTok Ads: R$ 149.08Code language: HTTP (http)Com a nossa base já criada, agora vem a criação do nosso código focado no modelo de atribuição position-based.
Implementação do Modelo Position-Based
def position_based_attribution(df, first_weight=0.4, last_weight=0.4):
"""
Implementação do Modelo Position-Based (Full Path)
O modelo funciona da seguinte forma:
1. Identifica o primeiro e último touchpoint de cada jornada
2. Atribui peso fixo para primeiro (40%) e último (40%)
3. Distribui o restante (20%) igualmente entre touchpoints intermediários
4. Para jornadas de apenas 1 touchpoint, atribui 100% do crédito
Parâmetros:
- df: DataFrame com dados de jornada
- first_weight: Peso do primeiro touchpoint (padrão: 0.4)
- last_weight: Peso do último touchpoint (padrão: 0.4)
Retorna: Series com valor atribuído por canal
"""
print(" Iniciando cálculo do modelo Position-Based...")
# Criando cópia dos dados para não modificar o original
df_position = df.copy()
# Etapa 1: Identificando posições na jornada
print(" Identificando primeiro e último touchpoints...")
df_position['is_first'] = df_position['touchpoint_order'] == 1
df_position['is_last'] = (df_position.groupby('customer_id')['touchpoint_order']
.transform('max') == df_position['touchpoint_order'])
# Etapa 2: Contando touchpoints intermediários por cliente
print(" Calculando touchpoints intermediários...")
middle_count = df_position.groupby('customer_id').apply(
lambda x: len(x) - 2 if len(x) > 2 else 0
)
df_position['middle_count'] = df_position['customer_id'].map(middle_count)
# Etapa 3: Função para calcular peso de cada touchpoint
def calculate_position_weight(row):
"""
Calcula o peso de cada touchpoint baseado na sua posição:
- Se for único touchpoint: 100% (1.0)
- Se for primeiro: peso configurado (padrão 40%)
- Se for último: peso configurado (padrão 40%)
- Se for intermediário: peso restante dividido pelo número de intermediários
"""
if row['is_first'] and row['is_last']:
# Jornada de apenas 1 touchpoint
return 1.0
elif row['is_first']:
# Primeiro touchpoint da jornada
return first_weight
elif row['is_last']:
# Último touchpoint da jornada
return last_weight
else:
# Touchpoint intermediário
if row['middle_count'] > 0:
remaining_weight = 1 - first_weight - last_weight
return remaining_weight / row['middle_count']
else:
return 0
# Etapa 4: Aplicando cálculo de peso
print(" Calculando pesos por posição...")
df_position['weight'] = df_position.apply(calculate_position_weight, axis=1)
# Etapa 5: Calculando valor atribuído
print(" Calculando valores atribuídos...")
df_position['attributed_value'] = (df_position['conversion_value'] *
df_position['weight'])
# Etapa 6: Agregando resultados por canal
print(" Agregando resultados por canal...")
attribution_results = df_position.groupby('channel')['attributed_value'].sum()
print(" Cálculo concluído com sucesso!")
return attribution_results, df_position
# Executando o modelo Position-Based
print(" APLICANDO MODELO POSITION-BASED")
print("=" * 50)
attribution_results, detailed_data = position_based_attribution(df)
# Mostrando resultados principais
print(f"\n RESULTADOS DO POSITION-BASED:")
print("=" * 40)
total_attributed = attribution_results.sum()
sorted_results = attribution_results.sort_values(ascending=False)
for channel, value in sorted_results.items():
percentage = (value / total_attributed) * 100
print(f"{channel:15} | R$ {value:>10,.2f} ({percentage:>5.1f}%)")
print(f"\n💼 Total Atribuído: R$ {total_attributed:,.2f}")
# Análise detalhada por tipo de touchpoint
print(f"\n ANÁLISE DETALHADA POR POSIÇÃO:")
print("=" * 45)
# Criando coluna position_type nos dados detalhados
detailed_data['position_type'] = detailed_data.apply(
lambda row: 'Único' if (row['is_first'] and row['is_last'])
else 'Primeiro' if row['is_first']
else 'Último' if row['is_last']
else 'Intermediário', axis=1
)
# Calculando distribuição por tipo de touchpoint
position_analysis = detailed_data.copy()
position_summary = position_analysis.groupby('position_type').agg({
'attributed_value': 'sum',
'customer_id': 'count'
}).round(2)
position_summary.columns = ['Valor_Total', 'Freq_Touchpoints']
position_summary['Percentual'] = (position_summary['Valor_Total'] /
position_summary['Valor_Total'].sum() * 100).round(1)
for position, row in position_summary.iterrows():
print(f"{position:12} | R$ {row['Valor_Total']:>10,.2f} ({row['Percentual']:>5.1f}%) | {row['Freq_Touchpoints']:>4} touchpoints") APLICANDO MODELO POSITION-BASED
==================================================
Iniciando cálculo do modelo Position-Based...
Identificando primeiro e último touchpoints...
Calculando touchpoints intermediários...
Calculando pesos por posição...
Calculando valores atribuídos...
Agregando resultados por canal...
Cálculo concluído com sucesso!
RESULTADOS DO POSITION-BASED:
========================================
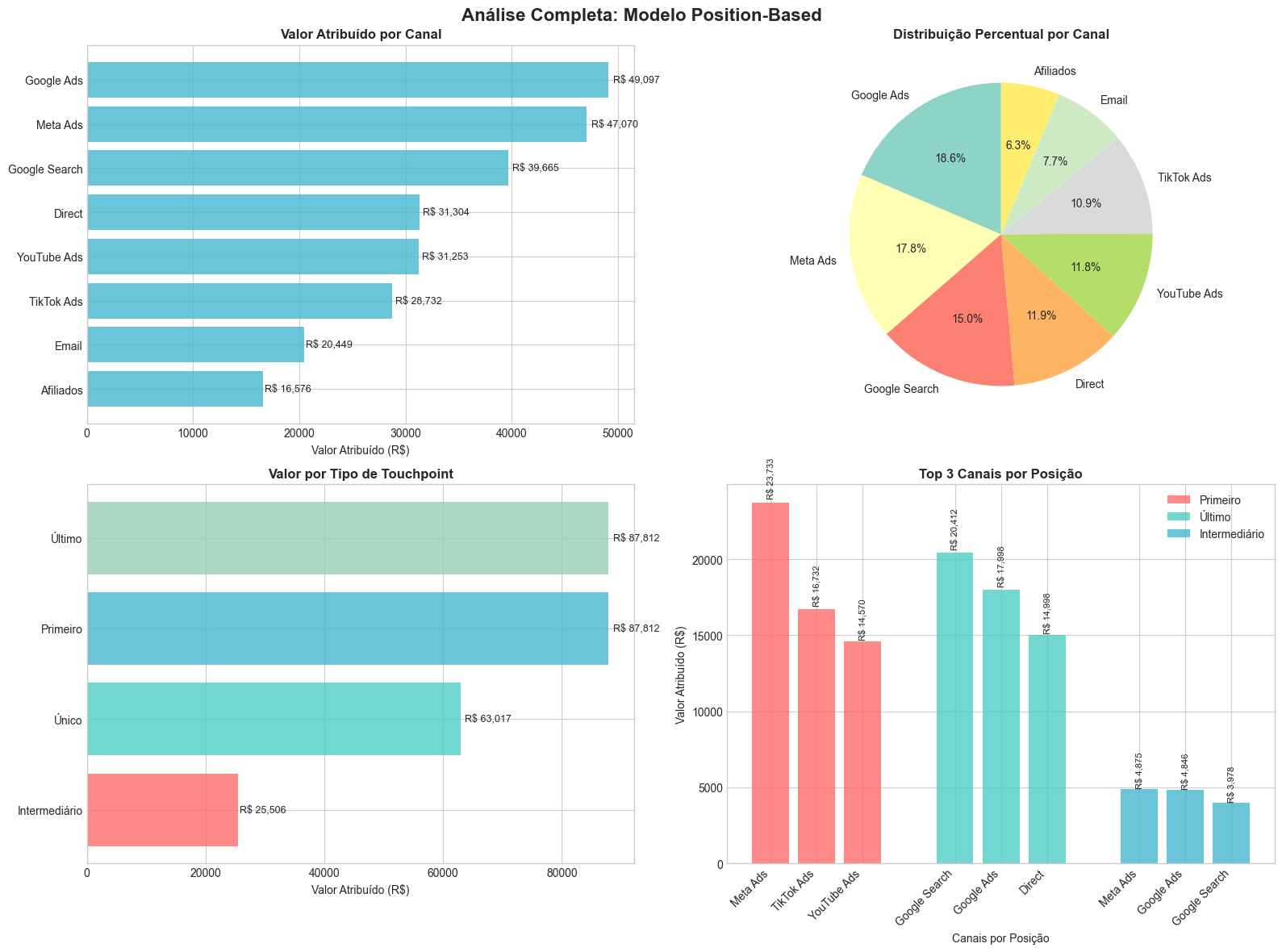
Google Ads | R$ 49,097.28 ( 18.6%)
Meta Ads | R$ 47,070.34 ( 17.8%)
Google Search | R$ 39,665.35 ( 15.0%)
Direct | R$ 31,304.41 ( 11.9%)
YouTube Ads | R$ 31,252.58 ( 11.8%)
TikTok Ads | R$ 28,732.07 ( 10.9%)
Email | R$ 20,449.05 ( 7.7%)
Afiliados | R$ 16,575.91 ( 6.3%)
Total Atribuído: R$ 264,147.00
ANÁLISE DETALHADA POR POSIÇÃO:
=============================================
Intermediário | R$ 25,506.46 ( 9.7%) | 1117.0 touchpoints
Primeiro | R$ 87,811.86 ( 33.2%) | 1142.0 touchpoints
Último | R$ 87,811.86 ( 33.2%) | 1142.0 touchpoints
Único | R$ 63,016.81 ( 23.9%) | 358.0 touchpointsCode language: HTTP (http)Visualização e Análise dos Resultados
Agora vamos criar visualizações para entender melhor como o modelo Position-Based distribui o valor entre os canais:
# Criando visualizações do modelo Position-Based
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle('Análise Completa: Modelo Position-Based', fontsize=16, fontweight='bold')
# Criando coluna position_type para análises detalhadas
detailed_data['position_type'] = detailed_data.apply(
lambda row: 'Único' if (row['is_first'] and row['is_last'])
else 'Primeiro' if row['is_first']
else 'Último' if row['is_last']
else 'Intermediário', axis=1
)
# 1. Valor atribuído por canal
channel_values = attribution_results.sort_values(ascending=True)
bars1 = ax1.barh(range(len(channel_values)), channel_values.values, color='#45B7D1', alpha=0.8)
ax1.set_yticks(range(len(channel_values)))
ax1.set_yticklabels(channel_values.index)
ax1.set_title('Valor Atribuído por Canal', fontweight='bold')
ax1.set_xlabel('Valor Atribuído (R$)')
# Adicionando valores nas barras
for i, bar in enumerate(bars1):
width = bar.get_width()
ax1.text(width + width*0.01, bar.get_y() + bar.get_height()/2,
f'R$ {width:,.0f}', ha='left', va='center', fontsize=9)
# 2. Distribuição percentual
percentages = (attribution_results / attribution_results.sum() * 100).sort_values(ascending=False)
colors = plt.cm.Set3(np.linspace(0, 1, len(percentages)))
wedges, texts, autotexts = ax2.pie(percentages.values, labels=percentages.index,
autopct='%1.1f%%', colors=colors, startangle=90)
ax2.set_title('Distribuição Percentual por Canal', fontweight='bold')
# 3. Análise por tipo de touchpoint
position_summary_plot = position_summary.sort_values('Valor_Total', ascending=True)
bars3 = ax3.barh(range(len(position_summary_plot)), position_summary_plot['Valor_Total'],
color=['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4'], alpha=0.8)
ax3.set_yticks(range(len(position_summary_plot)))
ax3.set_yticklabels(position_summary_plot.index)
ax3.set_title('Valor por Tipo de Touchpoint', fontweight='bold')
ax3.set_xlabel('Valor Atribuído (R$)')
# Adicionando valores nas barras
for i, bar in enumerate(bars3):
width = bar.get_width()
ax3.text(width + width*0.01, bar.get_y() + bar.get_height()/2,
f'R$ {width:,.0f}', ha='left', va='center', fontsize=9)
# 4. Top canais por posição
top_channels_by_position = detailed_data.groupby(['position_type', 'channel'])['attributed_value'].sum().reset_index()
# Foco nos 3 top canais para cada posição
position_types = ['Primeiro', 'Último', 'Intermediário']
colors_pos = ['#FF6B6B', '#4ECDC4', '#45B7D1']
x_pos = 0
x_labels = []
x_ticks = []
for i, pos_type in enumerate(position_types):
if pos_type in top_channels_by_position['position_type'].values:
pos_data = top_channels_by_position[top_channels_by_position['position_type'] == pos_type]
top_3 = pos_data.nlargest(3, 'attributed_value')
bars = ax4.bar(range(x_pos, x_pos + len(top_3)), top_3['attributed_value'],
color=colors_pos[i], alpha=0.8, label=pos_type)
# Labels dos canais
for j, (_, row) in enumerate(top_3.iterrows()):
x_labels.append(f"{row['channel']}")
x_ticks.append(x_pos + j)
# Valor na barra
ax4.text(x_pos + j, row['attributed_value'] + row['attributed_value']*0.01,
f'R$ {row["attributed_value"]:,.0f}',
ha='center', va='bottom', fontsize=8, rotation=90)
x_pos += len(top_3) + 1
ax4.set_title('Top 3 Canais por Posição', fontweight='bold')
ax4.set_xlabel('Canais por Posição')
ax4.set_ylabel('Valor Atribuído (R$)')
ax4.set_xticks(x_ticks)
ax4.set_xticklabels(x_labels, rotation=45, ha='right')
ax4.legend()
plt.tight_layout()
plt.show()
# Análise adicional: Performance por canal e posição
print(f"\n PERFORMANCE DETALHADA POR CANAL E POSIÇÃO:")
print("=" * 60)
channel_position_analysis = detailed_data.groupby(['channel', 'position_type']).agg({
'attributed_value': 'sum',
'customer_id': 'count'
}).round(2)
channel_position_analysis.columns = ['Valor_Atribuido', 'Frequência']
# Mostrando apenas os top canais
top_channels = attribution_results.nlargest(5).index
for channel in top_channels:
print(f"\n {channel}:")
if channel in channel_position_analysis.index.get_level_values('channel'):
channel_data = channel_position_analysis.loc[channel]
total_channel = channel_data['Valor_Atribuido'].sum()
for position, row in channel_data.iterrows():
percentage = (row['Valor_Atribuido'] / total_channel * 100) if total_channel > 0 else 0
print(f" {position:12} | R$ {row['Valor_Atribuido']:>8,.0f} ({percentage:>5.1f}%) | {row['Frequência']:>3} touchpoints")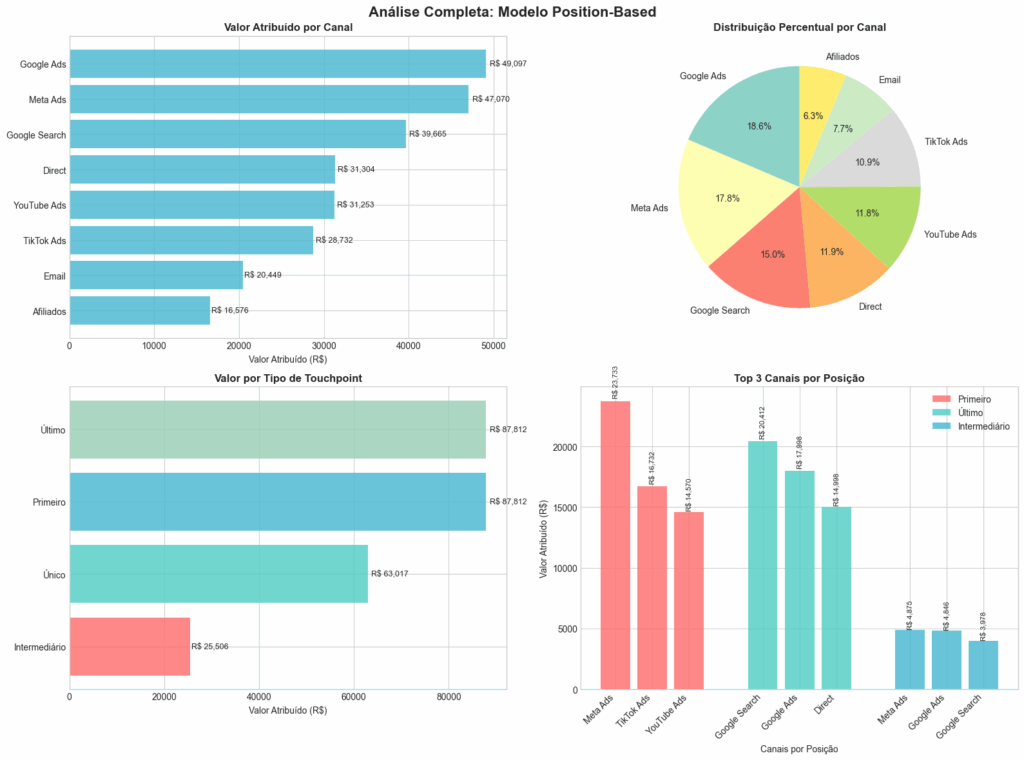
PERFORMANCE DETALHADA POR CANAL E POSIÇÃO:
============================================================
Google Ads:
Intermediário | R$ 4,846 ( 9.9%) | 208.0 touchpoints
Primeiro | R$ 12,834 ( 26.1%) | 180.0 touchpoints
Último | R$ 17,998 ( 36.7%) | 236.0 touchpoints
Único | R$ 13,419 ( 27.3%) | 57.0 touchpoints
Meta Ads:
Intermediário | R$ 4,875 ( 10.4%) | 194.0 touchpoints
Primeiro | R$ 23,733 ( 50.4%) | 324.0 touchpoints
Último | R$ 5,087 ( 10.8%) | 64.0 touchpoints
Único | R$ 13,375 ( 28.4%) | 79.0 touchpoints
Google Search:
Intermediário | R$ 3,978 ( 10.0%) | 185.0 touchpoints
Primeiro | R$ 8,805 ( 22.2%) | 113.0 touchpoints
Último | R$ 20,412 ( 51.5%) | 262.0 touchpoints
Único | R$ 6,471 ( 16.3%) | 32.0 touchpoints
Direct:
Intermediário | R$ 1,454 ( 4.6%) | 71.0 touchpoints
Primeiro | R$ 7,229 ( 23.1%) | 89.0 touchpoints
Último | R$ 14,998 ( 47.9%) | 194.0 touchpoints
Único | R$ 7,623 ( 24.4%) | 41.0 touchpoints
YouTube Ads:
Intermediário | R$ 2,852 ( 9.1%) | 125.0 touchpoints
Primeiro | R$ 14,570 ( 46.6%) | 173.0 touchpoints
Último | R$ 3,627 ( 11.6%) | 49.0 touchpoints
Único | R$ 10,204 ( 32.6%) | 64.0 touchpointsCode language: HTTP (http)Quando Usar o Modelo Position-Based?
flowchart TB
Start["Modelo Position-Based"]
Start --> F1["🎯 Estratégias<br/>Full-Funnel"]
F1 --> FF1["✔️ Awareness + performance"]
F1 --> FF2["✔️ Múltiplos canais simultâneos"]
F1 --> FF3["✔️ 3+ touchpoints em média"]
Start --> F2["📈 Ciclos de Compra<br/>Médios ou Longos"]
F2 --> CL1["✔️ E-commerce (R$200+ produtos)"]
F2 --> CL2["✔️ B2B e serviços"]
F2 --> CL3["✔️ Requer pesquisa pré-compra"]
Start --> F3["🏢 Negócios<br/>Omnichanais"]
F3 --> OM1["✔️ Social + search + email"]
F3 --> OM2["✔️ Valoriza descoberta e conversão"]
F3 --> OM3["✔️ Justificar investimento em awareness"]
classDef categoria fill:#f1f8e9,stroke:#33691e,stroke-width:1.5px;
class F1,F2,F3 categoria;Não é muito indicado para:
flowchart TB
F1["🏃♂️ E-commerce de Impulso"]
F1 --> P1["❌ Produto < R$100"]
F1 --> P2["❌ 1–2 touchpoints"]
F1 --> P3["💡 Use: Time Decay ou Last Touch"]
F2["🎯 Campanha Só Performance"]
F2 --> C1["❌ Só conversão imediata"]
F2 --> C2["❌ Sem budget para awareness"]
F2 --> C3["💡 Use: Last Touch"]
F3["📢 Só Awareness"]
F3 --> A1["❌ Foco só em descoberta"]
F3 --> A2["❌ Branding sem conversão"]
F3 --> A3["💡 Use: First Touch"]
classDef categoria fill:#ffebee,stroke:#b71c1c,stroke-width:1.5px;
class F1,F2,F3 categoria;Conclusões e Recomendações
- Dados realistas revelam o verdadeiro valor: Com dados que refletem investimento real por canal, padrões temporais e distribuições monetárias apropriadas, o Position-Based mostra resultados muito mais próximos da realidade do marketing digital;
- Equilibrio é a chave: O Position-Based reconhece que tanto awareness (Meta Ads, TikTok) quanto conversão (Google Search, Google Ads) são fundamentais para o sucesso;
- Flexibilidade estratégica: A capacidade de ajustar pesos (40%-40%-20% padrão) permite adaptar o modelo aos objetivos específicos de cada negócio;
- Padrões temporais e de investimento importam: Touchpoints podem se concentrar em horário específico a depender do tipo de negócio (por exemplo, um e-commerce ou uma pizzaria) com variações por canal que devem ser consideradas na análise;
- Justificativa clara para stakeholders: O modelo é intuitivo e fácil de explicar para equipes de marketing e executivos;
- Acionabilidade dos insights: Fornece direções claras sobre onde otimizar budget entre awareness, nurturing e conversão.
Checklist de Validação
Antes de confiar completamente nos resultados, valide:
- Distribuição temporal faz sentido com suas campanhas
- Valores por canal são proporcionais ao investimento
- Padrões de jornada refletem seu público-alvo
- Tickets médios estão alinhados com histórico
- Canais de awareness aparecem predominantemente no início
- Canais de conversão dominam posições finais
Este post fornece uma base para implementar o modelo Position-Based com dados artificiais. Aqui não foi feito nenhum processo de customização da análise para refletir particularidades dos negócio analisado. Lembre-se: a qualidade dos insights depende diretamente da qualidade dos dados de entrada.
Deixe um comentário