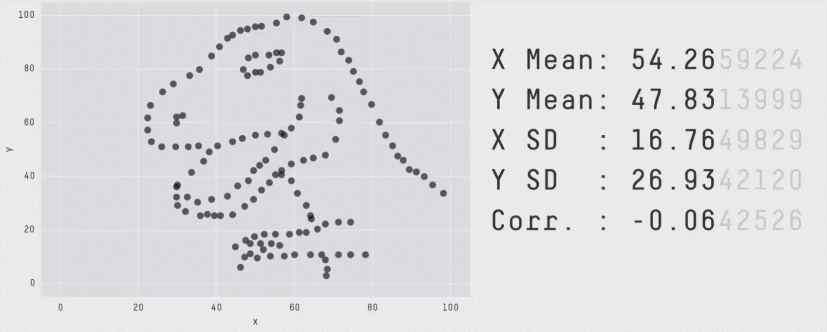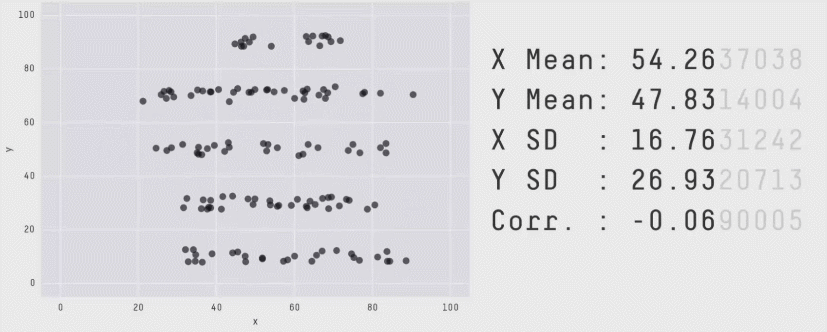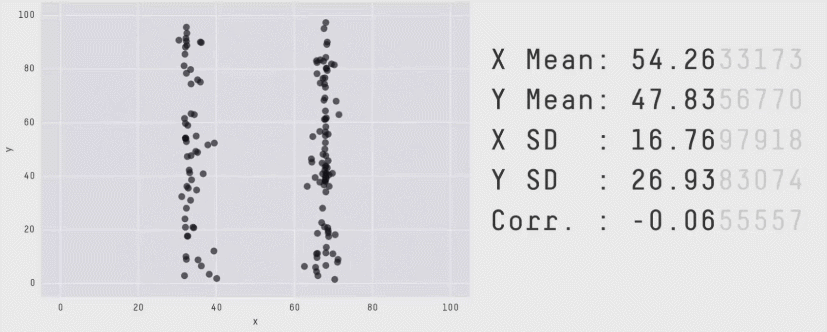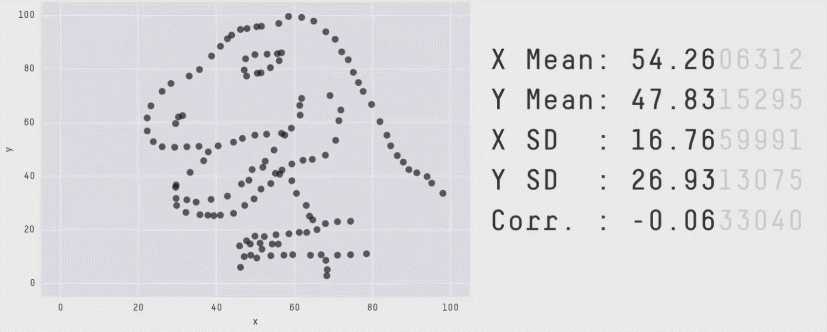
Esse segundo post entra na categoria “Seguindo o Tutorial” e é algo que descobri por acaso e percebi que tem uma importância enorme quando se trata de análises e visualização de dados, podendo gerar um problemão. Em suma, esse post é um tutorial utilizando o pacote Datasaurus e uma discussão sobre estatística básica!
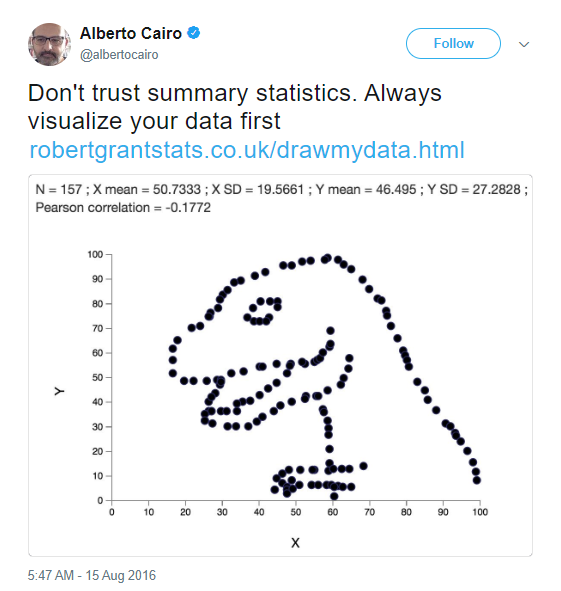
Tudo começou apenas como uma brincadeira do professor e infografista Alberto Cairo, que utilizou uma ferramenta criada por Robert Grant, um designer de estatística e visualização, para desenhar um dinossauro, que ficou conhecido como datasaurus. Esse site permite que você crie todos os pontos em um gráfico de dispersão e depois baixe os dados correspondentes.
Pegando carona nessa brincadeira, somos apresentados ao Quarteto de Anscombe. WTF??
O Quarteto de Anscombe é o nome dado a quatro conjuntos de dados que aparentam ser idênticos quando descritos por certas técnicas de estatística descritiva (como a média e a variância), mas que são muito distintos quando exibidos graficamente. Ele leva o nome do estatístico F.J. Anscombe que o publicou pela primeira vez em 1973, com o objetivo de demonstrar tanto a importância de se visualizar os dados antes de analisá-los quanto o efeito dos outliers nas propriedades estatísticas. (kibado da Wikipédia)
O jornalista **John Burn-Murdoch** criou uma ferramenta para exemplificar esse caso:
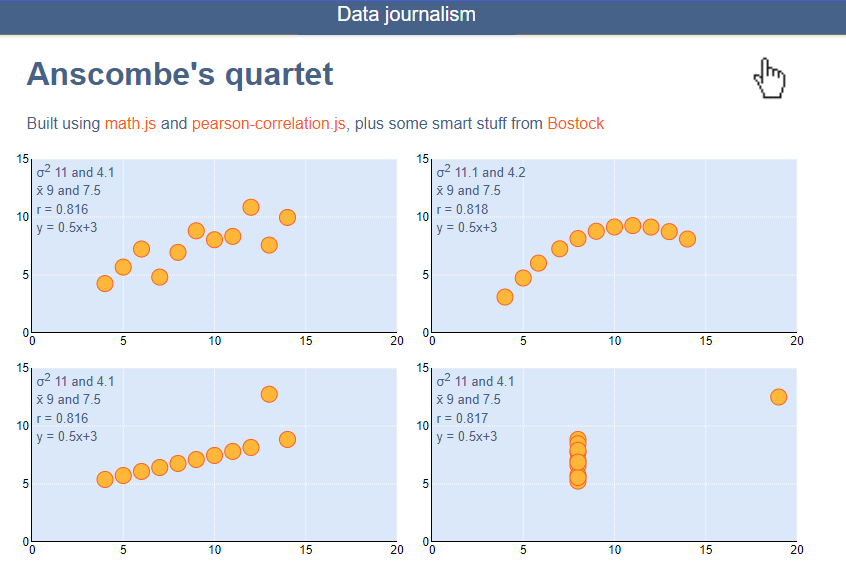
Clique para ir para a ferramenta!
Nota-se que a média, a variância e a correlação entre x e y em cada caso é muito próxima ou exata, pelo menos olhando de forma superficial, e geram gráficos totalmente diferentes.
Tendo como fio condutor essas discussões, os pesquisadores Justin Matejka e George Fitzmaurice escreveram um artigo muito interessante intitulado Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing, que aprofundam mais nesse tema e mostram outros casos interessantes.
Os datasets utilizados nesse artigo deram origem ao Datasaurus Dozen, conjunto de dados com estatísticas parecidas mas que originam gráficos totalmente diferentes e que podem ser reproduzidos utilizando o código abaixo:
#Instalando os pacotes
install.packages("datasauRus")
install.packages("ggplot2")
install.packages("devtools")
library(ggplot2)
library(datasauRus)
# Baixando os dados do Github do blog dos autores
devtools::install_github("stephlocke/datasauRus")
# Plotando os dados
ggplot(datasaurus_dozen,
aes(x=x,
y=y, colour=dataset))+
geom_point()+
theme_void()+
theme(legend.position = "none")+
facet_wrap(~dataset, ncol=3)Code language: PHP (php)O resultado é um conjunto de 13 gráficos que formam desenhos como esses aqui:
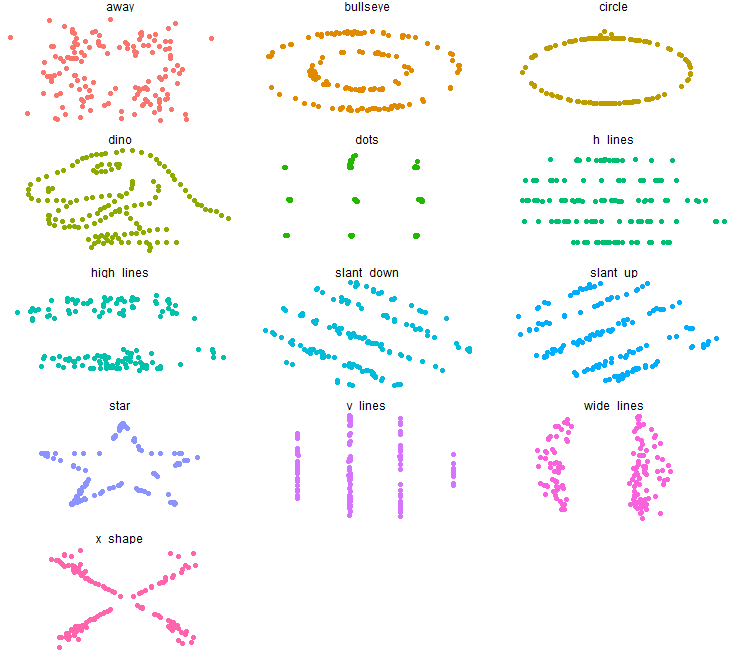
Sete distribuições de dados, mostradas como pontos de dados brutos (ou strip-plots), como box-plots e como violin-plots. Uma curiosidade interessante é que o Alberto Cairo mudou o nome da figura que ele criou para Anscombosaurus, em homenagem a Francis J. Anscombe.
Pra terminar, fica o aprendizado:
“Don’t trust summary statistics. Always visualize your data first!”.
Deixe um comentário