A Simulação de Monte Carlo é uma técnica computacional que utiliza números aleatórios para resolver problemas complexos através de amostragem repetida. O nome vem do famoso cassino de Monte Carlo em Mônaco, fazendo referência aos jogos de azar e aleatoriedade.
Esta técnica é amplamente utilizada em finanças, física, engenharia, marketing e ciência de dados para:
- Estimar probabilidades
- Calcular integrais complexas
- Avaliar riscos
- Otimizar processos
- Prever comportamentos futuros
No marketing digital, enfrentamos constantemente incertezas: taxas de conversão variam, custos por clique flutuam, e o comportamento do consumidor é imprevisível. A Simulação de Monte Carlo nos ajuda a modelar essas incertezas e tomar decisões mais informadas sobre alocação de budget e estratégias de campanha.
Exemplo Prático: Otimização de Budget e Previsão de ROAS
Vamos trabalhar com um cenário fictício: uma empresa precisa distribuir seu budget entre diferentes canais de marketing (Google Ads, Facebook Ads, Email Marketing, etc.) e quer prever o retorno sobre investimento (ROAS) considerando as incertezas de cada canal. Ao final, está disponibilizado o código em Python e em R.
Configuração Inicial e Importação de Bibliotecas
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
# Configuração para melhor visualização
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")O que este código faz: Importa as bibliotecas necessárias para análise de dados, visualização e cálculos estatísticos. A configuração de estilo melhora a aparência dos gráficos.
Definindo os Parâmetros dos Canais de Marketing
def criar_parametros_canais():
"""
Define os parâmetros de cada canal de marketing com suas incertezas
Retorna:
DataFrame com parâmetros de cada canal
"""
canais = {
'canal': ['Google Ads', 'Facebook Ads', 'Instagram Ads', 'Email Marketing', 'LinkedIn Ads'],
'cpc_medio': [2.5, 1.8, 1.5, 0.05, 5.0], # Custo por clique médio
'cpc_desvio': [0.5, 0.4, 0.3, 0.01, 1.0], # Desvio padrão do CPC
'ctr_medio': [0.035, 0.025, 0.022, 0.15, 0.028], # Taxa de clique média
'ctr_desvio': [0.008, 0.006, 0.005, 0.03, 0.007], # Desvio da CTR
'conversao_media': [0.03, 0.025, 0.02, 0.05, 0.04], # Taxa de conversão média
'conversao_desvio': [0.008, 0.007, 0.005, 0.015, 0.01], # Desvio da conversão
'ticket_medio': [150, 120, 100, 200, 300], # Valor médio da venda
'ticket_desvio': [30, 25, 20, 50, 80] # Desvio do ticket médio
}
return pd.DataFrame(canais)O que este código faz: Cria um DataFrame com os parâmetros de desempenho de cada canal de marketing, incluindo médias e desvios padrão para modelar a incerteza de cada métrica.
Simulação de Monte Carlo para um Canal
def simular_canal(nome_canal, budget, parametros, n_simulacoes=10000):
"""
Simula o desempenho de um canal de marketing usando Monte Carlo
Parâmetros:
nome_canal: nome do canal a simular
budget: orçamento alocado para o canal
parametros: DataFrame com parâmetros dos canais
n_simulacoes: número de simulações
Retorna:
DataFrame com resultados das simulações
"""
# Filtra parâmetros do canal
canal = parametros[parametros['canal'] == nome_canal].iloc[0]
# Arrays para armazenar resultados
resultados = {
'simulacao': range(n_simulacoes),
'cpc': np.zeros(n_simulacoes),
'ctr': np.zeros(n_simulacoes),
'taxa_conversao': np.zeros(n_simulacoes),
'ticket_medio': np.zeros(n_simulacoes),
'cliques': np.zeros(n_simulacoes),
'conversoes': np.zeros(n_simulacoes),
'receita': np.zeros(n_simulacoes),
'roas': np.zeros(n_simulacoes),
'lucro': np.zeros(n_simulacoes)
}
for i in range(n_simulacoes):
# Simula variáveis com distribuição normal truncada (valores positivos)
cpc = max(0.01, np.random.normal(canal['cpc_medio'], canal['cpc_desvio']))
ctr = np.clip(np.random.normal(canal['ctr_medio'], canal['ctr_desvio']), 0.001, 1)
conversao = np.clip(np.random.normal(canal['conversao_media'], canal['conversao_desvio']), 0.001, 1)
ticket = max(10, np.random.normal(canal['ticket_medio'], canal['ticket_desvio']))
# Calcula métricas
cliques = int(budget / cpc)
impressoes = int(cliques / ctr)
conversoes = int(cliques * conversao)
receita = conversoes * ticket
lucro = receita - budget
roas = (lucro / budget) * 100 if budget > 0 else 0
# Armazena resultados
resultados['cpc'][i] = cpc
resultados['ctr'][i] = ctr
resultados['taxa_conversao'][i] = conversao
resultados['ticket_medio'][i] = ticket
resultados['cliques'][i] = cliques
resultados['conversoes'][i] = conversoes
resultados['receita'][i] = receita
resultados['roas'][i] = roas
resultados['lucro'][i] = lucro
df_resultados = pd.DataFrame(resultados)
df_resultados['canal'] = nome_canal
return df_resultadosO que este código faz: Executa milhares de simulações para um canal específico, variando aleatoriamente as métricas de desempenho dentro de suas distribuições de probabilidade, calculando ROAS e lucro para cada cenário.
Análise de Resultados por Canal
def analisar_resultados_canal(df_simulacao, canal_nome):
"""
Cria visualizações e estatísticas dos resultados de simulação
"""
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle(f'Análise de Monte Carlo - {canal_nome}', fontsize=16)
# Distribuição do ROAS
ax1 = axes[0, 0]
ax1.hist(df_simulacao['roas'], bins=50, alpha=0.7, color='blue', edgecolor='black')
ax1.axvline(df_simulacao['roas'].mean(), color='red', linestyle='--',
label=f'Média: {df_simulacao["roas"].mean():.1f}%')
ax1.set_xlabel('ROAS (%)')
ax1.set_ylabel('Frequência')
ax1.set_title('Distribuição do ROAS')
ax1.legend()
# Distribuição do Lucro
ax2 = axes[0, 1]
ax2.hist(df_simulacao['lucro'], bins=50, alpha=0.7, color='green', edgecolor='black')
ax2.axvline(df_simulacao['lucro'].mean(), color='red', linestyle='--',
label=f'Média: R$ {df_simulacao["lucro"].mean():.2f}')
ax2.set_xlabel('Lucro (R$)')
ax2.set_ylabel('Frequência')
ax2.set_title('Distribuição do Lucro')
ax2.legend()
# Análise de Risco (Probabilidade de Prejuízo)
ax3 = axes[1, 0]
prob_prejuizo = (df_simulacao['lucro'] < 0).mean() * 100
prob_lucro = (df_simulacao['lucro'] >= 0).mean() * 100
ax3.bar(['Prejuízo', 'Lucro'], [prob_prejuizo, prob_lucro],
color=['red', 'green'], alpha=0.7)
ax3.set_ylabel('Probabilidade (%)')
ax3.set_title('Análise de Risco')
for i, v in enumerate([prob_prejuizo, prob_lucro]):
ax3.text(i, v + 1, f'{v:.1f}%', ha='center', fontweight='bold')
# Box plot de métricas chave
ax4 = axes[1, 1]
metricas = df_simulacao[['conversoes', 'receita', 'lucro']].copy()
metricas['receita'] = metricas['receita'] / 100 # Escala para melhor visualização
metricas['lucro'] = metricas['lucro'] / 100
metricas.boxplot(ax=ax4)
ax4.set_title('Variabilidade das Métricas (Receita e Lucro /100)')
ax4.set_ylabel('Valor')
plt.tight_layout()
plt.show()
# Estatísticas resumidas
print(f"\n=== Estatísticas para {canal_nome} ===")
print(f"ROAS Médio: {df_simulacao['roas'].mean():.2f}%")
print(f"ROAS Mediano: {df_simulacao['roas'].median():.2f}%")
print(f"Desvio Padrão ROAS: {df_simulacao['roas'].std():.2f}%")
print(f"Probabilidade de Prejuízo: {prob_prejuizo:.1f}%")
print(f"Value at Risk (5%): R$ {df_simulacao['lucro'].quantile(0.05):.2f}")
print(f"Lucro Esperado: R$ {df_simulacao['lucro'].mean():.2f}")O que este código faz: Cria visualizações detalhadas dos resultados da simulação, incluindo distribuições de ROAS e lucro, análise de risco e estatísticas resumidas para apoiar a tomada de decisão.
Otimização de Portfolio de Marketing
def otimizar_portfolio(budget_total, parametros, n_simulacoes=5000):
"""
Encontra a melhor alocação de budget entre canais usando Monte Carlo
"""
canais = parametros['canal'].values
n_canais = len(canais)
# Gera alocações aleatórias
n_portfolios = 1000
alocacoes = np.random.dirichlet(np.ones(n_canais), size=n_portfolios)
resultados_portfolio = []
for i, alocacao in enumerate(alocacoes):
roas_total = 0
lucro_total = 0
risco_total = 0
# Simula cada canal com sua alocação
for j, canal in enumerate(canais):
budget_canal = budget_total * alocacao[j]
if budget_canal > 0:
sim = simular_canal(canal, budget_canal, parametros, n_simulacoes=1000)
roas_medio = sim['roas'].mean()
lucro_medio = sim['lucro'].mean()
risco = sim['lucro'].std()
# Ponderação pelo budget
roas_total += roas_medio * alocacao[j]
lucro_total += lucro_medio
risco_total += risco * alocacao[j]
resultados_portfolio.append({
'portfolio': i,
'roas_esperado': roas_total,
'lucro_esperado': lucro_total,
'risco': risco_total,
'sharpe_ratio': lucro_total / risco_total if risco_total > 0 else 0,
'alocacao': alocacao
})
df_portfolios = pd.DataFrame(resultados_portfolio)
# Encontra portfolios ótimos
melhor_roas = df_portfolios.loc[df_portfolios['roas_esperado'].idxmax()]
melhor_sharpe = df_portfolios.loc[df_portfolios['sharpe_ratio'].idxmax()]
return df_portfolios, melhor_roas, melhor_sharpeO que este código faz: Testa múltiplas combinações de alocação de budget entre canais, calculando o retorno esperado e o risco de cada portfolio para encontrar as alocações ótimas.
Visualização da Fronteira Eficiente
def plotar_fronteira_eficiente(df_portfolios, melhor_roas, melhor_sharpe):
"""
Plota a fronteira eficiente de portfolios de marketing
"""
plt.figure(figsize=(12, 8))
# Scatter plot de todos os portfolios
scatter = plt.scatter(df_portfolios['risco'],
df_portfolios['lucro_esperado'],
c=df_portfolios['sharpe_ratio'],
cmap='viridis',
alpha=0.6,
s=50)
# Destaca portfolios ótimos
plt.scatter(melhor_roas['risco'], melhor_roas['lucro_esperado'],
color='red', s=200, marker='*',
label='Melhor ROAS', edgecolor='black', linewidth=2)
plt.scatter(melhor_sharpe['risco'], melhor_sharpe['lucro_esperado'],
color='orange', s=200, marker='*',
label='Melhor Sharpe Ratio', edgecolor='black', linewidth=2)
plt.colorbar(scatter, label='Sharpe Ratio')
plt.xlabel('Risco (Desvio Padrão do Lucro)')
plt.ylabel('Lucro Esperado (R$)')
plt.title('Fronteira Eficiente - Portfolios de Marketing')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
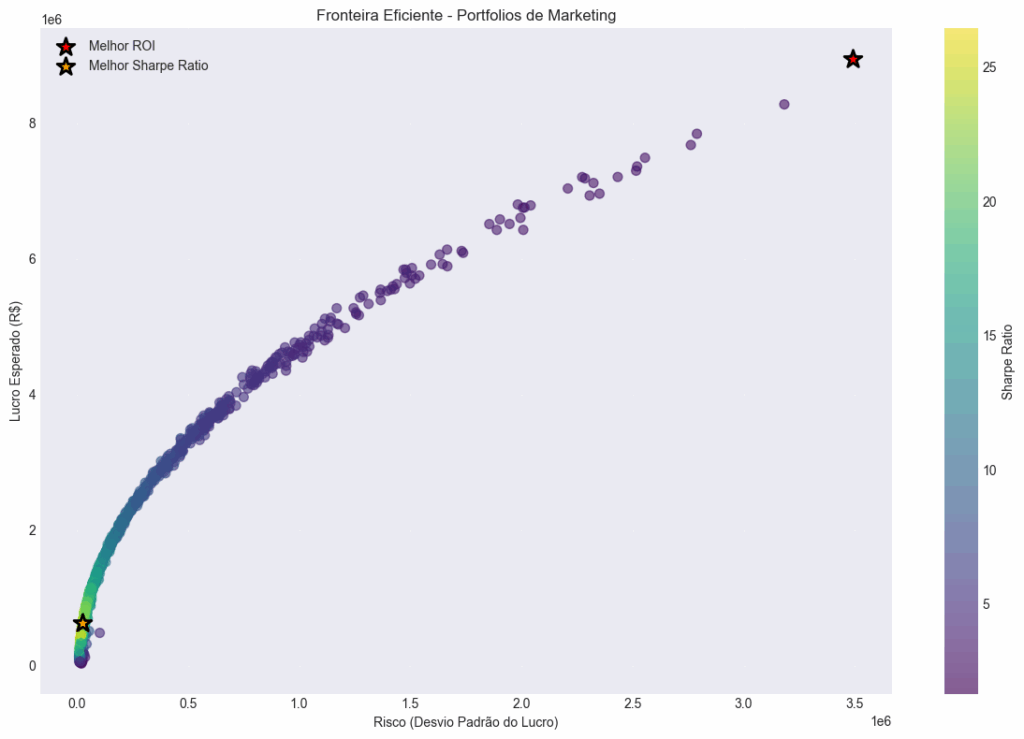
plt.show()O que este código faz: Cria um gráfico mostrando a relação risco-retorno de diferentes alocações de budget, destacando os portfolios ótimos segundo diferentes critérios.
# Define parâmetros
parametros = criar_parametros_canais()
budget_total = 50000 # R$ 50.000
# 1. Análise individual de cada canal
print("=== ANÁLISE INDIVIDUAL DOS CANAIS ===")
for canal in parametros['canal']:
print(f"\nSimulando {canal}...")
simulacao = simular_canal(canal, budget_total/5, parametros, n_simulacoes=10000)
analisar_resultados_canal(simulacao, canal)
=== Estatísticas para Google Ads ===
ROAS Médio: 86.88%
ROAS Mediano: 75.72%
Desvio Padrão ROAS: 78.57%
Probabilidade de Prejuízo: 9.7%
Value at Risk (5%): R$ -1736.16
Lucro Esperado: R$ 8688.49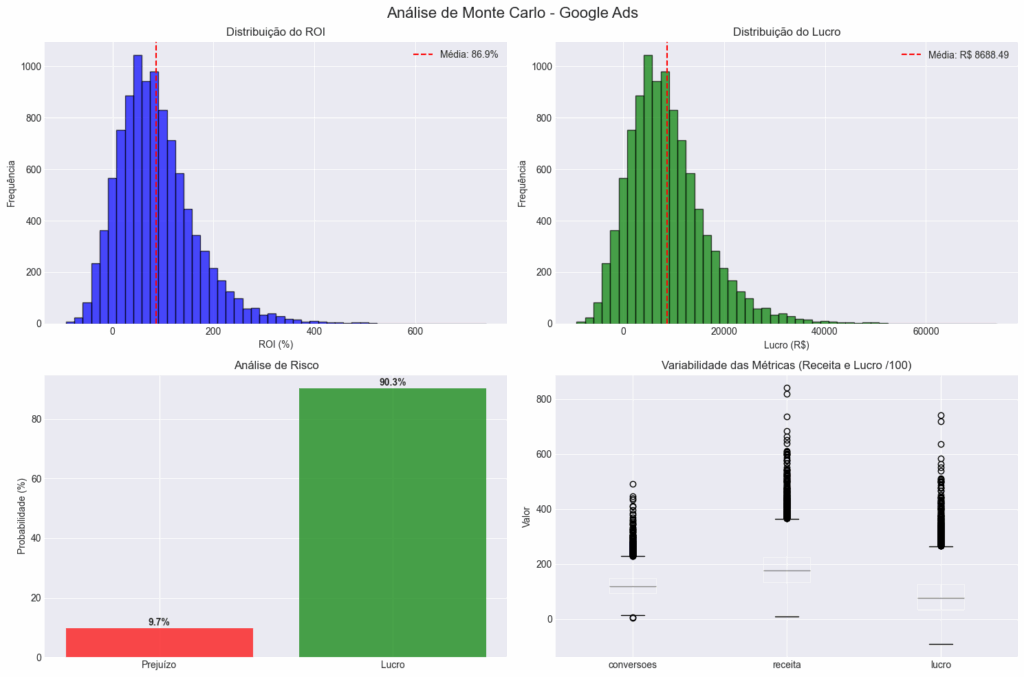
# 2. Otimização de portfolio
print("\n=== OTIMIZAÇÃO DE PORTFOLIO ===")
df_portfolios, melhor_roas, melhor_sharpe = otimizar_portfolio(budget_total, parametros)
# 3. Visualização da fronteira eficiente
plotar_fronteira_eficiente(df_portfolios, melhor_roas, melhor_sharpe)
# 4. Exibição das alocações ótimas
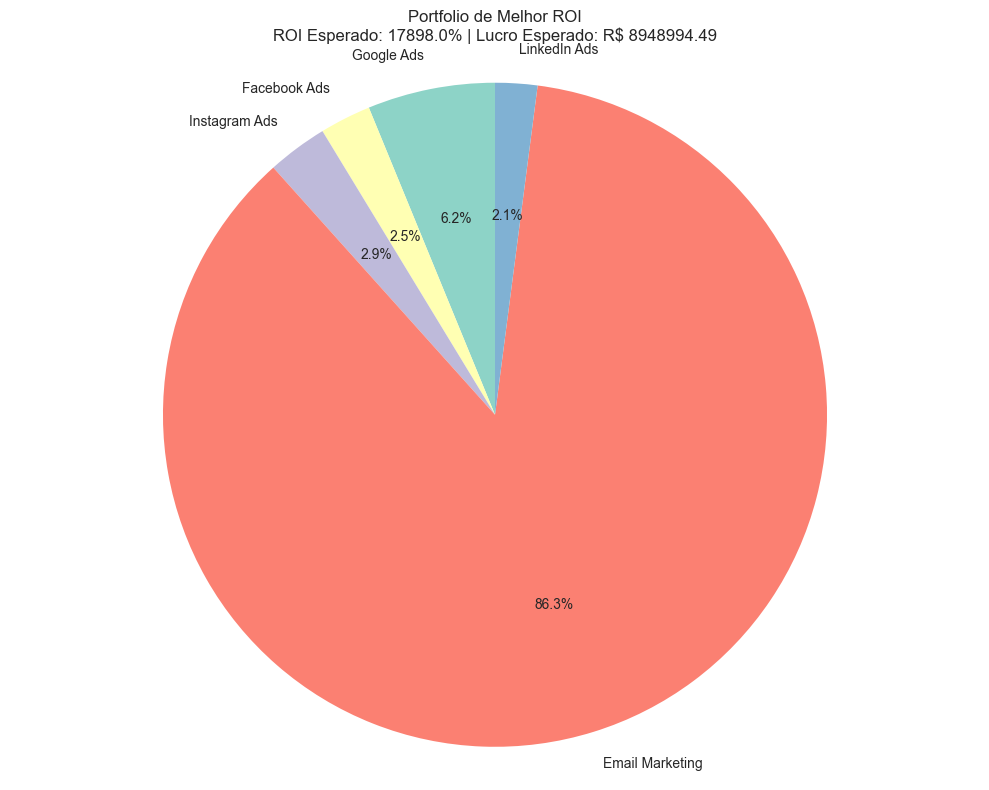
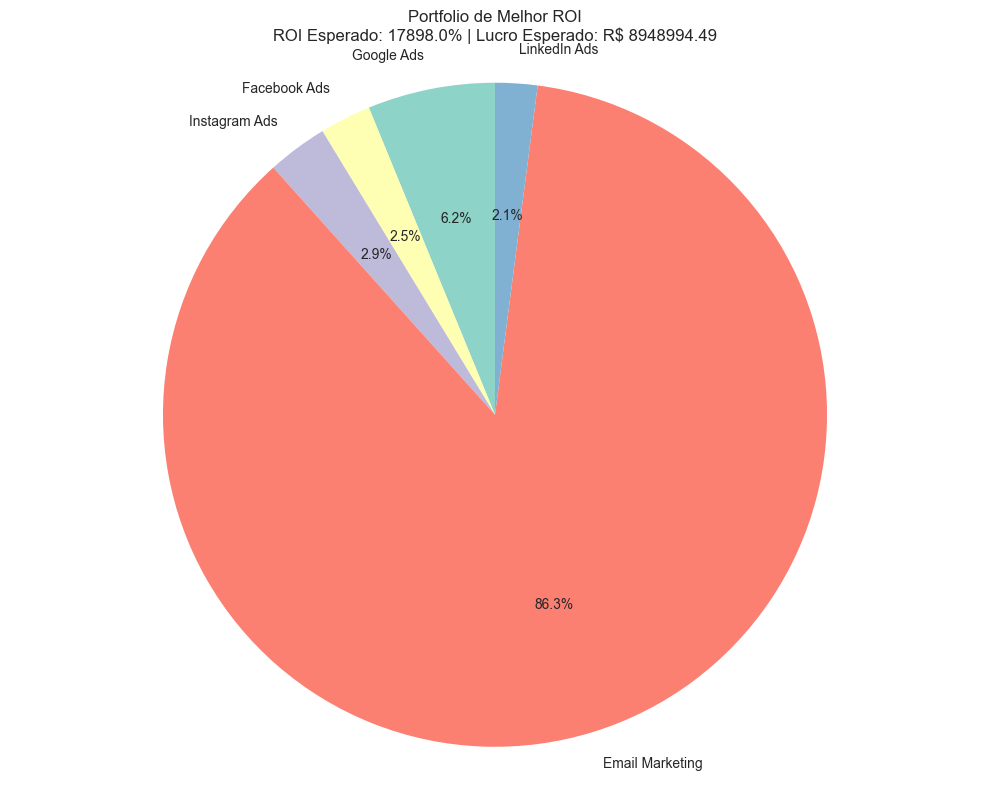
exibir_alocacao_otima(melhor_roas, parametros, "Portfolio de Melhor ROAS")
exibir_alocacao_otima(melhor_sharpe, parametros, "Portfolio de Melhor Sharpe Ratio")
# 5. Comparação de estratégias
print("\n=== COMPARAÇÃO DE ESTRATÉGIAS ===")
print(f"Portfolio de Melhor ROAS:")
print(f" - ROAS Esperado: {melhor_roas['roas_esperado']:.2f}%")
print(f" - Lucro Esperado: R$ {melhor_roas['lucro_esperado']:.2f}")
print(f" - Risco: R$ {melhor_roas['risco']:.2f}")
print(f"\nPortfolio de Melhor Sharpe Ratio:")
print(f" - ROAS Esperado: {melhor_sharpe['roas_esperado']:.2f}%")
print(f" - Lucro Esperado: R$ {melhor_sharpe['lucro_esperado']:.2f}")
print(f" - Risco: R$ {melhor_sharpe['risco']:.2f}")=== COMPARAÇÃO DE ESTRATÉGIAS ===
Portfolio de Melhor ROAS:
- ROAS Esperado: 17897.99%
- Lucro Esperado: R$ 8948994.49
- Risco: R$ 3491372.13
Portfolio de Melhor Sharpe Ratio:
- ROAS Esperado: 1260.24%
- Lucro Esperado: R$ 630120.98
- Risco: R$ 23835.62Conclusão
No caso acima temos apenas uma sinplificação, um modelo mais robusto levaria em consideração uma distribuição não-normal, uma vez que temos métricas que não assume valor negativo (não existe investimento, cpc e ctr negativo) e tal. De qualquer forma, a Simulação de Monte Carlo é uma ferramenta poderosa para resolver problemas complexos através de amostragem aleatória. Permitindo:
- Quantificar Incertezas: Modelar variações em métricas como CPC, CTR e taxa de conversão
- Avaliar Riscos: Calcular probabilidades de prejuízo e Value at Risk
- Otimizar Alocações: Encontrar a distribuição ideal de budget entre canais
- Comparar Estratégias: Avaliar trade-offs entre retorno e risco
Benefícios práticos:
- Tomada de decisão baseada em dados probabilísticos
- Identificação de canais com melhor relação risco-retorno
- Planejamento de budget com margem de segurança
- Previsões mais realistas considerando incertezas do mercado
A escolha entre maximizar ROAS ou Sharpe Ratio depende do perfil de risco da empresa: startups podem preferir alto ROAS aceitando mais risco, enquanto empresas estabelecidas podem priorizar consistência (Sharpe Ratio).
Deixe um comentário